Vol. 1, Ōä¢7, 2014
Riabenko E.A. Multiplicative method for non-negative matrix factorization with AB-divergence and its convergence // Machine Learning and Data Analysis. 2014. V. 1, Ōä¢ 7. Pp. 800-816.Multiplicative method for non-negative matrix factorization with AB-divergence could converge to non-stationary point when the elements of matrices approach zero. We propose a modified multiplicative method that bounds the matrices from zero by constant 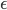 , and prove not only monotonic descent, but the fact that its every limiting point is a stationary point of the modified bounded problem. Setting particular elements of the resulting matrix to zero yields the solution that is
, and prove not only monotonic descent, but the fact that its every limiting point is a stationary point of the modified bounded problem. Setting particular elements of the resulting matrix to zero yields the solution that is 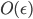 -close to the stationary point of the original problem. For a special case of Frobenius norm we prove that the method always converges.
-close to the stationary point of the original problem. For a special case of Frobenius norm we prove that the method always converges.
Kushnir O.A., Seredin O.S., Stepanov A.V. Experimental study of regularization and approximation parameters for binary images skeletons // Machine Learning and Data Analysis. 2014. V. 1, Ōä¢ 7. Pp. 817-827. The article is devoted to the problem of avoiding the complexity and instability of binary images continuous skeletons by means of the regularization and approximation coefficients. The algorithm for computing the minimal diameter of circle circumscribed about the skeleton is suggested. Minimal diameter is a scaled multiplier which is used for computation of the approximation coefficient. Experimental study of how the regularization and approximation parameters affect the skeleton topology has been done, and assumptions about the appropriate values for finding the base subgraph of skeleton for the stable shape description are proposed.
Matveev I.A., Trekin A.N. Vehicle detection in aerial color images // Machine Learning and Data Analysis. 2014. V. 1, Ōä¢ 7. Pp. 828-834. The paper presents an algorithm for detecting cars in color images obtained by aerial photography. The key to the solution is that majority of cars are painted in single color and have similar size and shape. This allows to discriminate the areas occupied by vehicles from the background as regions with certain color characteristics and geometrical properties. Regions in image are constructed by hierarchical clustering induced by color likelihood and spatial neighborhood. The algorithm was tested with the set of urban and rural images, which contains totally 2226 vehicles.
Larin A.O., Seredin O.S., Kondrashov V.V. Combining of one-class classifiers for segmentation images with microassembly layout objects // Machine Learning and Data Analysis. 2014. V. 1, Ōä¢ 7. Pp. 835-842. Automation solution for laser trimming of resistive element facilities requires presegmentation of microassembly topology elements based on image obtained from a video camera. Because the specifics of the system, the application of standard methods of image segmentation can be difficult. In this paper, to solve this problem, the authors proposed an approach based on using Support Vector Data Description method and LBP (local binary patterns) features.
Djukova E., Nikiforov A., Prokofyev P. Statistically Efficient Parallel Scheme for Dualization Algorithms // Machine Learning and Data Analysis. 2014. V. 1, Ōä¢ 7. Pp. 843 - 853. Background: Dualization is a fundamental problem in discrete mathematics. It is equivalent to irredicible coverings enumeration of a given boolean matrix. This problem is of high computational complexity. Therefore, using of parallel computing is practical. However, existing approaches to dualization algorithms parallelizing are trivial and not much efficient. Methods: An efficient on average parallel scheme (B-scheme) for asymptotically optimal dualization algorithms is suggested. The proposed scheme is based on statistical analysis of irreducible coverings set. Results: The experiments show that B-scheme provides a balanced load of processors on the average and that gained speedup of parallel dualization algorithm is almost the highest possible. Concluding Remarks: B-scheme outperforms other considered approaches to dualization algorithms parallelization. However, the number of processors used by B-scheme should be rather small; otherwise, no performance improvement is gained. Getting rid of processors number limitation and expanding the range of aproach applicability will be a topic of future works.
Pushnyakov A.S. On combinatorial bounds for maximal  -partitions of a finite metric space // Machine Learning and Data Analysis. 2014. V. 1, Ōä¢ 7. Pp. 854 - 862. A finite metric space
-partitions of a finite metric space // Machine Learning and Data Analysis. 2014. V. 1, Ōä¢ 7. Pp. 854 - 862. A finite metric space 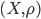 is studied. By -cluster we mean a subset of
is studied. By -cluster we mean a subset of 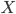 with diameter at most . Let there be an upper bound for the number of distances which are greater than . We consider lower bounds for maximal cardinality of
with diameter at most . Let there be an upper bound for the number of distances which are greater than . We consider lower bounds for maximal cardinality of 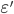 -cluster. An important question is to find dependence between and . It is shown that in case where
-cluster. An important question is to find dependence between and . It is shown that in case where 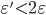 we cannot guarantee any linear bound. In case where
we cannot guarantee any linear bound. In case where 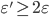 the best possible bound is obtained. A maximal -partition is a partition into -clusters constructed according to greedy procedure described below. Using Hall's marriage theorem we prove existence of special matching between every two elements of maximal -partition. Considering maximal matching between -cluster with maximal cardinality and its complement we can calculate number of pairs
the best possible bound is obtained. A maximal -partition is a partition into -clusters constructed according to greedy procedure described below. Using Hall's marriage theorem we prove existence of special matching between every two elements of maximal -partition. Considering maximal matching between -cluster with maximal cardinality and its complement we can calculate number of pairs 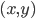 such that
such that 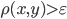 and obtain lower bound for maximal cardinality of -cluster. In some particular cases value of can be decreased. For instance, in case of Euclidean metric we can assume
and obtain lower bound for maximal cardinality of -cluster. In some particular cases value of can be decreased. For instance, in case of Euclidean metric we can assume 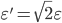 and obtain linear bound. However, it is unknown whether this bound could be improved.
and obtain linear bound. However, it is unknown whether this bound could be improved.
Panov A.I. Algebraic Properties fo Recogniton Operators in Modeling Visual Perception // Machine Learning and Data Analysis. 2014. V. 1, Ōä¢ 7. Pp. 863 - 874. The article discusses the problem of visual perception modelling and presents the main principles of top-down models developed as a result of neurophysiological research. These principles include (a) hierarchical information representation; (b) the ability to predict the type of the incoming signal; (c) the ability to recognize both static and dynamic scenes; (d) the controllability of the perception process. The basis of most perception models is a so called recognizing unit. In this paper it is formally defined according to the described principles. Recognition operators are built upon the recognizing unit algorithm which is proposed in the article. Classical static and dynamic recognition problems are formulated. Correctness of the operators is examined using Yu. I. ZhuravlevŌĆÖs algebraic theory. The article presents theorems about correctness of several operator classes. These theorems indicate the possibility to build a hierarchy of basic elements that can recognize the incoming signals. This, in its turn, indicates the existence of the corresponding learning algorithm that uses the recognizing blocks. The obtained results prove that (a) the recognizing blocks algorithm properly models human perception subsystem and does not contradict the modern pattern recognition theory; (b) it is possible to use Yu. I. ZhuravlevŌĆÖs algebraic theory to verify if the operators are correct.
Derbenev N.V., Kozliuk D.A., Nikitin V.V., Tolcheev V.O. Experimental Research of Near-Duplicate Detection Methods for Scientific Papers // Machine Learning and Data Analysis. 2014. V. 1, Ōä¢ 7. Pp. 875 - 884. Near-duplicate detection problem focuses on determining pairs of semantically equivalent documents which differ syntactically. For scientific papers the case in question corresponds either to plagiarism among different authors, or to a single author publishing ŌĆ£clonedŌĆØ papers to achieve higher citation rank. Given a set of document pairs with a priori expert opinions, efficiency of any near-duplicate detection method can be measured by the number of correct near-duplicate detections (recall) and false-positive detection count (precision). These metrics cannot be maximized simultaneouslyŌĆöcomplex criterion are used. Improvements can be made by choosing a method with the highest precision for a given recall and then preprocessing documents in favor of specifics of the selected algorithm. We propose an efficiency criteria limiting both recall and precision. We then form a sample set of title and abstract pairs (publically available bibliographic descriptions) and acquire expert assessments for them. After that, we use the sample set to evaluate performance of various known near-duplicate detection methods subjected to the criteria proposed. Precision of 74% at 90% recall for Jaccard and generalized similarity coefficients appeared to be reachable by removing frequent words of authorsŌĆÖ vocabulary from documentsŌĆÖ abstracts. Generalized Similarity Coefficient (GSC) method was introduced in our former work. Along with Winnowing, GSC scored best in method comparison without preprocessing. Results were checked by examining a subset of documents with full texts available (about 20% of sample set). Verification confirmed high sustained precision by revealing documents with near-duplicate titles and abstracts to have identical content.
Dvoenko S.D., Pshenichny D.O. Optimal correction of metrical violations in matrices of pairwise comparisons // Machine Learning and Data Analysis. 2014. V. 1, Ōä¢ 7. Pp. 885 - 890. In modern data mining experimental data usually represented as objectsŌĆÖ mutual pairwise comparisons. The condition of correct immersion of set objects in metrical space in the absence of the initial feature space is non-negative definiteness of matrix of pairwise comparisons between these objects. In this case, similarities are interpreted as scalar products and dissimilarities as distances. This paper offers a method of correction for normalized matrices of similarities, so the corrected matrix is positively definite and minimally deviated from the initial one. Proposed method detects objects, which contribute violations in the metrics. Pairwise comparisons of these objects with subset of other objects are corrected. This approach also allows to choose this subset of elements. It is proved that such a correction always exists and can be optimal. In contrast to traditional approach based on Karhunen-Loeve discrete decomposition proposed method is able to correct only few of matrix elements.
Zagoruiko N. G., Kutnenko O.A., Zyryanov A.O., Levanov D.A. Learning to recognition without overfitting // Machine Learning and Data Analysis. 2014. V. 1, Ōä¢ 7. Pp. 891 - 901. The problem of dealing with overfitting of recognition algorithms is one of the central problems in data mining. The algorithm that selects the most informative objects and features and generates a signal at the point in which overfitting starts is described. At this signal the learning process stops. To calculate the similarity between objects the ternary relative measure called the function of rival similarity (FRiS) is used. Selecting informative features is made by the algorithm FRiS-Grad. Learning includes the consistent increase of number of reference objects ("stolps") and the formation of clusters of objects closed to stolps in a fixed feature space. On each step of augmentation of number of stolps the estimation of quality of the description of sample (or divisibility of classes) is calculated. The hypothesis that the in the inflection point of the curve describing the separability of classes, may signal about the beginning of overfitting is formulated and confirmed. The algorithm FRiS-C-GRAD of learning without overfitting is developed on this basis. A method of decision-making that takes into account the weight of clusters is proposed. The results of testing of the algorithm on simulated problems are described. Using FRiS-function has been useful in constructing of decision rules, automatic classification (taxonomy) and selecting informative features and in obtaining quantitative estimation of compactness. The utility of using this measure of similarity for addressing the protection of overfitting is illustrated in this paper.
Kornilov F.A. Detection of structural differences in images: algorithms and methods of research // Machine Learning and Data Analysis. 2014. V. 1, Ōä¢ 7. Pp. 902 - 919. The article is devoted to the problem of structural differences detection at satellite images, taken at different times. Structural changes here means appeared or dissapeared groundŌĆÖs objects. The starting point of the inversigation is morphological analysis of images theory by Yu. P. Pytiev. In the work, the general notion of the imageŌĆÖs structure and structural difference are introduced. Several algorithms for solving the problem for grayscale images are proposed, and also the morphological projectorŌĆÖs modification for dealing with color images is given. For the algorithm based on the morphological projector in the case of imageŌĆÖs distorsion with additive noise, the method for computing the output imageŌĆÖs values distribution is given, for the first algorithm. Also the formula for optimal threshold and estimation of the I and II-type errors are given. The computational technique for comparison of the algorithms of structure changes detections in images is formulated. For a such purpose the special mathematical model is introduced. This model provides an opportunity for maximally move closer to applied real problems. The proposed technique gives the way for computing the best value of the true positives rate (false alarm rate), with given fixed maximal value of the false alarm rate (minimal value of the true positives rate). Also, the comparison results of the performance of the proposed algorithms are given. Experiments with real data demonstrates the proposed algorithms are good enough for applications.
Karkishchenko A.N., Mnukhin V.B. Symmetrization of the image points defined by statistical sampling // Machine Learning and Data Analysis. 2014. V. 1, Ōä¢ 7. Pp. 920 - 935. The paper is devoted to methods of constructing reflectionally and rotationally symmetrical configurations of characteristic points in an image calculated from a certain set of given points that do not possess this property. The problem has many applications and is called the problem of symmetrization. In previous studies, we examined methods for its solution, provided that each point analyzed is given with some estimate of its position, which may not coincide with the true one. Solutions have been proposed for cases of reflectional and rotational symmetry with varying degrees of a priori uncertainty. Optimality of the solutions is in the fact that symmetrization is achieved in a minimum Euclidean metric deviation of "symmetrized" points from the original locations. In contrast to previous publications in this paper we consider the more general case when the points are specified by statistical samples of coordinates of their possible position. It requires, respectively, the "statistical" understanding of the optimality of solutions. Therefore, the methods proposed in this paper, being based on statistical samples, are available for constructing symmetrical configurations of points which are optimal in the sense that they have the highest probability density of appearance. The paper also shows that this problem can be reduced to the standard setting of the minimization problem in a space with Mahalanobis metric. It is also proposed normalized (from zero to one) measure to assess the degree of symmetry of the source statistics, which naturally follows from the proposed methods. To illustrate the methods, the results of modeling are given in the article.
Vol. 1, Ōä¢8, 2014
Murashov D.M., Berezin A.V., Ivanova E. Comparing images of paintings using informative fragments // Machine Learning and Data Analysis. 2014. V. 1, Ōä¢ 8. Pp. 941 - 948. The problem of comparing images for the purpose of attribution of fine-art paintings is considered. Features that are used in this work, describe texture of a painting and characterize an artistic style of a painter. The feature space includes a histogram of orientation angles of grayscale image ridges and a histogram of simple neighborhood orientation based on the local structure tensor. A procedure for feature extraction is developed. An information-theoretical dissimilarity measure based on Kullback-Leibler divergence is used for comparing informative image fragments. A method for comparing images of paintings using dissimilarity measure values between fragments is proposed. The method is tested on images of portraits created in 18-19 centuries. The paintings are compared using three fragments segmented in a particular image. The results of the experiments showed that the difference between portraits painted by the same artist is substantially smaller than one between portraits painted by different authors. The proposed technique may be used as a part of techno-technological description of fine art paintings for attribution. The future research will be aimed at extending feature space, developing a technique for locating informative fragments, augmenting image dataset, and testing the developed method on augmented dataset.
Lepskiy A.E. Comparison of distorted histograms by probability methods // Machine Learning and Data Analysis. 2014. V. 1, Ōä¢ 8. Pp. 949 - 965. This paper is devoted to study of stability of comparison of histograms with help of different probability methods. The comparison of histograms is necessary in many applied problems of data processing. The comparison of type ŌĆØmore-lessŌĆØ is considered in this paper. But the histograms may be distorted. The nature of these distortions can be different. Then we have a problem to find the conditions on distortions under which the comparison of the two histograms is not changed. There are many approaches to comparison of histograms. The three popular probabilistic methods of comparison of histograms are considered in this paper: comparison of mathematical expectations, comparison with help of principle of stochastic dominance, comparison with help of stochastic precedence. We consider the interval distortions of histograms in this paper. The necessary and sufficient conditions of preservation for comparison of distorted histograms found with respect to different probability indices of comparison. The description of set of admissible distortions preserving the comparison of two histograms found. The characteristics of stability of histograms to distortion are introduced. These characteristics are calculated for histograms of USE (Unified State Exam) of applicants admitted in 2012 in Russian universities. It is shown that the stability of comparison of histograms to distortion can does not correspond to the values of difference index of comparison (margin). The found conditions invariability of comparing histograms can be used to estimate the reliability of results of different rankings, data processing, etc. in terms of different types of uncertainty: stochastic uncertainty, the uncertainty associated with the distortion of the data in filling data gaps, etc.
Karkishchenko A.N., Mnukhin V.B. Topological filtration for digital images recognition and symmetry analysis // Machine Learning and Data Analysis. 2014. V. 1, Ōä¢ 8. Pp. 966 - 987. A number of methods for digital images processing (say, the Fourier-Mellin transform method) is based on the formal adaptation of the continuous Fourier transform properties to the discrete case. As a result, aliasing errors occur, and it is highly important to control it. In the paper, aliasing is considered as a topological effect, caused by different properties of frequency domains of continuous and discrete Fourier transforms. Indeed, the continuous frequency domain may be considered as a sphere, but it is a torus in the discrete case. We define a torus winding operator, that transforms functions in a plane (or a sphere) to functions on a torus.We show that the discrete spectrum of an image is the discretization of the winding of a torus by the continuous Fourier transform of the piecewise-constant approximation of the image. As a corollary, DFT is expanded into a series, whose initial term is the continuous Fourier transform discretization, and next terms are higher harmonic effects. The results are applied to the problem of finding the ŌĆ£optimalŌĆØ rotations in discrete frequency and spatial domains. Another application of the stated results is a technique to reduce systematic errors in frequency domain-based methods for digital images recognition, registration and symmetry analysis. It is based on the continuous Fourier transform of the piecewise-constant approximation of an image instead of DFT. For this, an algorithm for topological filtration of the spectrum of an digital image is presented. The complexity of the algorithm is the same as for FFT.
Genrikhov I.E. About splitting criteria used for synthesis of decision trees // Machine Learning and Data Analysis. 2014. V. 1, Ōä¢ 8. Pp. 988 - 1017. The new of splitting criterion are proposed ŌĆö criterion of maximization share objects of different classes (Maximum Differences of Classes (MDC)). On the model data particular qualities of criterion MDC are analysed in comparison with such famous criteria as: Gain, GainRatio, Gini Index, Twoing and criteria of uniform partition. On a large number of real world tasks the structural and recognizable properties of a decision tree are investigated to depending on the criteria branching: depth of tree, average depth of tree leaves, ŌĆ£balanceŌĆØ of tree (differences between a depth and average depth of tree leaves), weighted depth the descriptions distribution of training objects on the leaves of tree, ŌĆ£optimalŌĆØ distribution of training objects on tree leaves (absolute difference between a average depth of tree leaves and weighted depth the descriptions distribution of training objects on the leaves of tree), quality of tree (with method ŌĆ£leave-one-outŌĆØ and analysis margins distribution of training objects), number of tree leaves. It is shown that the new splitting criterion allows to receive more optimum of a decision tree in comparison with the considered criteria.
Matveev I.A., Novik V.P. New method of selecting best iris template from sequence // Machine Learning and Data Analysis. 2014. V. 1, Ōä¢ 8. Pp. 1018 - 1026. A new way of selecting best template from a group of templates generated from image sequence is presented for the problem of iris identification. The method is based on analysis of distance matrix of the template group. Comparison is performed with the standard approach, which uses quality features of the source images. It is pointed that usually the image quality methods are developed for the task of poor image rejection and thus are not well suited for the task of best image selection. Numerical tests are carried out with several public domain databases with total number of iris images over 70000. The tests show that the proposed method has slightly better quality of selected templates. At that, it does not require development of additional quality measure but uses existing inter-template distance calculation.
Chykhradze K.K., Korshunov A.V., Buzun N.O., Kuzyurin N.N. On a Model of Social Network with User Communities for Distributed Generation of Random Social Graphs // Machine Learning and Data Analysis. 2014. V. 1, Ōä¢ 8. Pp. 1027 - 1047. In the field of social community detection, it is commonly accepted to utilize graphs with reference community structure for accuracy evaluation. The method for generating large random social graphs with realistic structure of user groups is introduced in the paper. The proposed model satisfies some of the recently discovered properties of social community structure: dense community overlaps, superlinear growth of number of edges inside a community with its size, and power law distribution of user-community memberships. Further, the method is by-design distributable and showed near-linear scalability in Amazon EC2 cloud using Apache Spark implementation. The generated graphs possess properties of real social networks and could be utilized for quality evaluation of algorithms for community detection in social graphs of more than 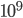 users.
users.
Djukova E.V., Prokofjev P.A. Construction and investigation of new asymptotically optimal algorithms for dualization // Machine Learning and Data Analysis. 2014. V. 1, Ōä¢ 8. Pp. 1048 - 1067. An improvement and experimental justification of the asymptotically optimal approach to discrete enumeration problems are presented in this paper. The approach aims at effective on average algorithms construction. Dualization is considered a fundamental enumeration problem. It is equivalent to irreducible coverings enumeration of a given boolean matrix. A column set 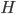 of a boolean matrix
of a boolean matrix 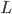 is called an irreducible covering if 1) submatrix
is called an irreducible covering if 1) submatrix 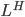 formed by columns from contains no zero-filled rows; 2) contains each row from the list:
formed by columns from contains no zero-filled rows; 2) contains each row from the list: 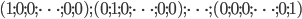 . Column set satisfying the condition 2) is called compatible. Asymptotically optimal dualization algorithms enumerate with polynomial delay the ŌĆ£maximalŌĆØ compatible column sets. Such algorithms construct a column set at each step. The solutions set is updated if the column set satisfies 1) and has not been found at previous steps. Otherwise this step is considered ŌĆ£extraŌĆØ. The proportion of ŌĆ£extraŌĆØ steps tends to zero for almost all boolean matrices of a given size as matrix size increases. Asymptotically optimal dualization algorithms RUNC, RUNC-M and PUNC are suggested in this paper. These algorithms are shown to outperform the prior dualization algorithms. Despite the absence of estimates of the complexity of asymptotically optimal dualization algorithms for the worst case, asymptotically optimal approach is superior to other approaches, according to the experiments on real problems.
. Column set satisfying the condition 2) is called compatible. Asymptotically optimal dualization algorithms enumerate with polynomial delay the ŌĆ£maximalŌĆØ compatible column sets. Such algorithms construct a column set at each step. The solutions set is updated if the column set satisfies 1) and has not been found at previous steps. Otherwise this step is considered ŌĆ£extraŌĆØ. The proportion of ŌĆ£extraŌĆØ steps tends to zero for almost all boolean matrices of a given size as matrix size increases. Asymptotically optimal dualization algorithms RUNC, RUNC-M and PUNC are suggested in this paper. These algorithms are shown to outperform the prior dualization algorithms. Despite the absence of estimates of the complexity of asymptotically optimal dualization algorithms for the worst case, asymptotically optimal approach is superior to other approaches, according to the experiments on real problems.
Dvoenko S.D., Sang D.V. Evaluation of parametric acyclic Markov models for dependent objects // Machine Learning and Data Analysis. 2014. V. 1, Ōä¢ 8. Pp. 1068 - 1076. In modern theory of pattern recognition objects are often classified with regard to interrelations (data coherence, spatial and temporal cohesion, etc.) between them. Markov random fields (MRFs) are most popular to model such objects. The interrelations between neighboring objects are represented by an adjacency graph. In general, the inference in MRFs is NP-hard when the adjacency graph contains cycles. The main idea of this work is to replace the graph with cycles by a linear combination of a finite or countable set of acyclic (treelike) parametric Markov models, for which the problem of recognizing MRFs can be efficiently solved. We propose a simplified cross-validation procedure to statistically evaluate the quality of solutions and to adjust the parameters of the linear combination, in which the Markov ones are treated as hyper-parameters.
Dorofeyuk A.A., Dorofeyuk Y.A., Pokrovskaya I.V., Chernyavskiy A.L. Independent multivariate expertise in the weakly formalized management systems research // Machine Learning and Data Analysis. 2014. V. 1, Ōä¢ 8. Pp. 1077 - 1088. The modification of the collective multivariate expertise method (CMVE) was developed, adequate to the interdepartmental type problems, called as the method of an independent collective multivariate expertise (IMVE). The main and essential difference of the developed IMVE method from the CMVE method is that in the process of examination, there are developed not the solutions of the original problem in general but identifing and developing solutions to relatively independent problems associated with the initial objective, comprehensive solution which ensures the solution of the original problem. Implementation of the method of IMVE is divided into 5 main stages: creating the list of candidates; the relatively independent list of the expertise problems; the assessment of the potential experts competence; establishment of expert commission, including issues on which there are different opinions; and the work of expert commissions. In conclusion, consulting group, which conducted the IMVE method, forms the final draft of the problem solution. The independent collective multivariate expertise method was used for solving 2 large-scale applied problems ŌĆö organization and management of the interregional bus services market problem and the task of creating intelligent control systems medical-diagnostic processes in the large-scale medical clinic. The successful solution of the two major applied problems of a new type confirms the high efficiency of the developed method.
Emelyanov G.M., Mikhaylov D.V., Kozlov A.P. Formation of the representation of topical knowledge units in the problem of their estimation on the basis of open tests // Machine Learning and Data Analysis. 2014. V. 1, Ōä¢ 8. Pp. 1089 - 1106. The problem considered is an automated formation of necessary and sufficient feature set of knowledge unit estimated by means of open form test assignments. Such tests assume testee answer in natural language. The most effective open form test implementation implies the known structure of natural-language forms of expression of expert knowledge. For extraction of such forms, it is necessary to analyze equivalent within the meaning descriptions of one and the same fact of topical area in given natural language. The main task here is finding the most rational plan to express the meaning of the expert in the right answer. At that, the meaning eventually must be presented in maximally compact volume of text data. It is relatively to this data that the correctness of testee answer is estimated. The given work represents how it is possible to select this data on the basis of extraction and classification of structural units, defining the lexical-syntactic relations relatively to the set of semantically equivalent phrases in natural language, describing some fact of test topical area. Rating of detected links is carried out on the basis of frequency of their occurrence, as well as values of root-mean-square deviation distance in linear series of the phrase between words as part of the link relatively to the given set of semantically equivalent phrases. The offered by the authors method of finding of these links allows to minimum fourfold reduce the volume of text information necessary for estimation of testee answer correctness to open form test question.
Varlamov M.I., Korshunov A.V. Computing semantic similarity of concepts using shortest paths in Wikipedia link graph // Machine Learning and Data Analysis. 2014. V. 1, Ōä¢ 8. Pp. 1107 - 1125. A measure of semantic similarity between concepts characterizes the degree of relatedness between their senses. Texterra system uses Wikipedia-based Dice semantic similarity measure for word sense disambiguation. Since concepts in Texterra are Wikipedia articles, one is interested in precise link-based semantic similarity measures. This work presents a global semantic similarity measure based on distances between concepts in Wikipedia link graph. Graph distance is estimated as the shortest path length between a pair of nodes (Wikipedia articles). The difference of the proposed method from existing measures based on shortest paths is in the usage of disparity of different link types. Here, a special data structure is used which allows one to compute the shortest pasts efficiently with acceptable memory costs. Compared to Dice measure, usage of shortest paths allows both to increase the correlation between computed and expert similarity and to achieve better results in the word sense disambiguation task. Also, it is demonstrated that regular and category links are the most relevant for semantic similarity estimation. This work shows that distances between articles in Wikipedia link graph can provide an effective basis for computing semantic similarity between corresponding concepts.
Lange M.M., Ganebnykh S.N. An Efficiency of Hierarchical Classification in Terms of Fidelity-Complexity Ratio // Machine Learning and Data Analysis. 2014. V. 1, Ōä¢ 8. Pp. 1126 - 1136. Most of existent approaches are limited by two-class classification models using exhaustive search scheme for the decision. The present approach is intended for multiclass classification model and is based on guided search scheme for the decision. The examined classifier is constructed in a space of original tree-structured object representations and uses a multilevel network of template objects taken at sequential resolution levels. A parametric family of decision algorithms based on hierarchical and exhaustive search for the nearest template decision is examined. For the above decision algorithms, analytical estimates of the computational complexities are obtained. Also, experimental estimates of recognition error rates are calculated using a composite image source of faces, hand gestures, and signatures. The comparative dependences of the error rate on the computational complexity are shown. The proposed methodology yields a new approach to efficient metric classification of the image-based objects provided that the number of classes is sufficiently large and this approach can be applied for recognition of biometric images.
Vol. 1, Ōä¢9, 2014
Dvoenko S.D. Bi-partial objective function for clustering a set of elements in terms of pairwise comparisons // Machine Learning and Data Analysis. 2014. V. 1, Ōä¢ 9. Pp. 1141 - 1153. In a featureless case, a set of objects is represented only by results of pairwise mutual comparisons in the form of a distance, similarity, or kernel-based matrix. Nevertheless, the cluster centers can be implicitly represented by its distances to other objects without the feature space itself. The present author proposes k-means clustering without computations of cluster centers at all. This novel procedure, referred to as the k-meanless clustering, makes permutations on the similarity or distance square matrix resulting in the same clustering for both featureless and feature-based cases. In addition, new bi-partial objective function combines intracluster distances with intercluster similarities and needs to be minimized or in the dual form combines intracluster similarities with intercluster distances and needs to be maximized. Based on bi-partial approach, the clustering quality can be improved relative to the usual objective function. The k-means idea is very popular in the form of many heuristic aggregating procedures where cluster centers cannot be explicitly presented. Therefore, they are only suboptimal versions of the k-means. The proposed k-meanless clustering is the correct version of them.
Mandrikova O.V., Zalyaev T.L. Modeling of of cosmic ray variations and allocation of anomalies based on a combination of wavelet transform with neural networks // Machine Learning and Data Analysis. 2014. V. 1, Ōä¢ 9. Pp. 1154 - 1167. Valuable information about the topology change of the geomagnetic field during magnetic storms is provided by study of the dynamics of cosmic rays. Observed on the EarthŌĆÖs surface variations of cosmic rays are the integral result of various solar, heliospheric and atmospheric phenomena and have a complex internal structure. The most significant changes in the parameters of cosmic rays are caused by coronal mass ejections and the following changes in the parameters of the interplanetary field and the solar wind. In disturbed periods recorded parameters of the environment have a complex nonstationary structure, contain non-smooth local features, which occur at random time moments and carry important information about the studied processes. Lack of theoretical apparatus providing an adequate description of the analyzed data, leads to an inevitable loss and distortion of the information and requires advanced methods, among which are of great importance methods of pattern recognition and digital signal processing. Based on a combination of multiresolution wavelet decompositions with neural networks we propose a method of approximation of the cosmic rays time course and the allocation of anomalous variations (Forbush effects) that occur during periods of high solar activity . The method allows to study in detail the structure of the data, to allocate informative components and build their approximation based on neural network. On the basis of the proposed method for the stations "Novosibirsk", "Apatity" and "Athens" were built software systems for neural network approximation of typical variations of cosmic rays and the analysis of data in the periods of strong magnetic storms. Application of the method allowed us to study the dynamic characteristics of the processes and to allocate anomalous effects related to solar activity. Application of the method in conjunction with other methods and approaches allow better perform the assessment of the state of space weather.
Chuchupal V.J., Korenchikov A.A. Improving speech recognition accuracy by means of word pronunciation modeling // Machine Learning and Data Analysis. 2014. V. 1, Ōä¢ 9. Pp. 1168 - 1179. Pronunciation variation modeling evidently has a big potential as a simple way to significally improve the accuracy of automatic speech recognition. At the same time the reported improvements in accuracy obtained with pronunciation variation models in experiments are still far from the expected ones. We explore the advantages of the so-called explicit pronunciation variation models as an approach for improvement of natural Russian speech recognition accuracy. The probabilistic pronunciation variation model is formally defined as well as the methods of its parameter estimation. We show that the effect of use of explicit pronunciation variation models is very dependent on the speech material type. Evaluation on the corpus with Russian read and planned speech shows a negligible effect of using the models. At the same time the evaluation of pronunciation models on spontaneous Russian speech reveals substantial improvement of automatic speech recognition accuracy. Despite a big promises there are need a lot of efforts to develop pronunciation variation models for speech recognition that will effectively account for speaker and speaking style, accents and dialects. Nevertheless right now the pronunciation model of explicit type can show substantial improvement of recognition accuracy on natural speech recognition task.
Kuznetsov E.N., Anashkina A.A., Esipova N.G., Tumanyan V.G. Cluster analysis for spatial contacts of amino acid residues of proteins with DNA nucleotides // Machine Learning and Data Analysis. 2014. V. 1, Ōä¢ 9. Pp. 1180 - 1199. We classified amino acids on the basis of protein-DNA contacts geometry and statistics. Amino acid residues have a variety of properties and can simultaneously belong to different classes. So, it was interesting to use the classification of amino acids with different types of fuzzing. Voronoi-Delaunay tessellation was used to determine the spatial relationship between the amino acids of proteins and DNA nucleotides from 1937 protein-DNA complexes. General variation approach was used for the classification of amino acids with different types of fusion. It was shown that about 30% of all contacts between amino acids and nucleotides in protein-DNA complexes are not random. Crisp classification methods showed the existence of clustering invariants of amino acids at the lowest level of association. It was shown by fuzzy classification methods that six classes are optimal for protein-DNA recognition task. Fuzzy classification of amino acids data can be used to construct the substitution matrix for DNA-binding protein sequences and protein-DNA binding analysis.
Fedotov N.G., Syemov A.A., Moiseev A.V. Intelligent capabilities hypertrace transform: Constructing features with predetermined properties // Machine Learning and Data Analysis. 2014. V. 1, Ōä¢ 9. Pp. 1200 - 1214. In recent decades, the emphasis in the analysis and pattern recognition shifts from two-dimensional (2D) to three-dimensional (3D) images, because 3D design allows to use more information about the object. Three-dimensional modeling gives possibility to see object from different angles, in particular, allows to analyze its spatial form. In this article, a new approach to the 3D objects' recognition based on modern methods of stochastic geometry and functional analysis is proposed. This method has many advantages and data mining capabilities. Thus, features have hypertriplet composite structure, which provide not only easy machine implementation of this algorithm, but construction of a large number of features. Due to building a rigorous mathematical model, the analyst can construct analytical and not intuitive features, describing each object class and their features (in particular, constructing geometric features). Three-dimensional trace transform allows to create invariant description of spatial object, which is more resistant to distortion and coordinate noise than the description obtained as a result of the object normalization procedure. Possibility of regulating constructed features' properties signi cantly increases intellectual capabilities of 3D trace transform that is undoubtedly its advantage. Proof developed theory and the mathematical model is variety constructed theoretical examples of hypertriplet features having described particular properties. In the article, the role of functional included in composite structure of hypertriplet feature is analyzed. Extended possibilities of 3D trace transform, in particular, extracting in the same scanning technique the information about the spatial position and orientation of 3D object, are described. Description of many ways of 3D image mining is proposed. For example, one of the intellectual abilities of the proposed method is a high-level preprocessing, processing, and postprocessing of 3D images in one scanning technique.
Filipenkov N.V., Petrova M.A. On the analysis of multidimensional time series // Machine Learning and Data Analysis. 2014. V. 1, Ōä¢ 9. Pp. 1215 - 1231. In this paper an approach for discovering rules in nonstationary finite-valued multidimensional time series is discussed. It allows one to discover rules that are slightly changing their structure over time. A measure of rule similarity is introduced and studied as a weight on the graph of rules. This paper is focusing on the results of the application of the discussed algorithm to the modeled and real problems. The experiments on the model problems show that the approach allows to mine the hidden rules efficiently even under high noise conditions. The experiments on the modeled multidimensional time series show that using the rules similarity measure in the quality function significantly increases the forecast accuracy. During the experiments the weight range for maximum data mining quality is identified. The analysis of real time series based on the discussed approach show the algorithm's efficiency for short-term forecasting. In addition to that the algorithm is also solving the data mining problem while finding the rules describing the interconnection of the univariate time series. The application of the discussed approach for forecasting the processes with slightly changing rules on modeled and real data shows the efficiency of the developed algorithms for the analysis of multidimensional time series with slightly changing rules.
Ostapets A.A. Smartphone location recognition using mobile sensors // Machine Learning and Data Analysis. 2014. V. 1, Ōä¢ 9. Pp. 1232 - 1245. This article focuses on the use of machine learning methods in the task of determining the location of the phone (bag, pocket, hand). This problem is important in many practical applications, such as automatic on / off energy-intensive services at various positions of the mobile device. The aim of this study was to evaluate and validate the possibility of detecting mobile phone place. The data were collected using the accelerometer and the gyroscope. The whole classification process (preprocessing, feature extraction and classification) is presented in this article. Acceleration data acquired suffers from changes due accelerometer noise which needs to be eliminated. It's solved using low-pass filter. Primary features that are often used when working with the signals from the sensors are described in this paper. Feature selection was conducted on real data, and the best features were selected. Algorithms have trained using phone orientation independent features to recognize several locations of the phone. It's was tested by two different datasets. The paper presents an experimental study and comparative analysis of algorithms. It is shown that the proposed approach achieved 88% accuracy on the used datasets.
Chulichkov A.I., Yuan B. Estimation of minimum possibility of losses and minimax estimation: a comparative analysis // Machine Learning and Data Analysis. 2014. V. 1, Ōä¢ 9. Pp. 1246 - 1260. The estimation of function values at specified points in its domain of definition based on the measurement results of the finite set of functionals is posed and solved. The measurements are distorted by a finite error. It is shown that with the finite error can be estimated only finite dimensional component of unknown function. Exact finite-dimensional model, underlying the construction of required assessments is proposed. Two methods for estimation are discussed. The first method minimizes the maximal error of the estimation of each value of the function at a given point. It is believed that the measurement error of each linear functional may take any value within a given interval. For each of the estimated value of a function the interval that contains this value was constructed. The minimax estimate is the midpoint of this interval, and the error is the half of its length. The ends of each interval are determined as solutions of linear programming problems. The second method of estimation is based on theoretical-possibility measurement models. It is believed that large values of the measurement error of each functional less possible than small. The estimation criterion is the possibility of losses. Estimation method minimizes this criterion and is reduced to the solution of a linear programming problem. The estimates of the minimum possible losses and the estimates that minimize the maximum error of each value of function is compared. Differences between the minimax estimates and estimates of the minimum possible losses are discussed. An example of estimation of specter based on the data of real spectrometric experiment is given.
Kharatsidi O.A. Human activity recognition based on accelerometer and gyro data // Machine Learning and Data Analysis. 2014. V. 1, Ōä¢ 9. Pp. 1261 - 1272. In the last few years the performance of smartphones has been growing rapidly. They have become capable of carrying out relatively complex computation in real time. We consider a problem of human physical activity recognition based on the data from sensors on wearable devices. The classical approach is to split the accelerometer signals into fixed-width windows, classify them independently and then combine the classification responses into a single one for the whole sample. Classification models may vary from Naive Bayes classifiers to Neural Nets. The two common types of the features are statistical metrics (moments, correlations etc) and Fourier coefficients. The method introduced in this paper utilizes the same approach but unlike the most common case, it uses a mixture of three standard classification models: Logistic Regression, Nearest Neighbour and Random Forest built up on the Fourier coefficients absolute values. Feature selection based on the trained Logistic Regression coefficients is applied to fit the rest two models independently. We test our method on the USC-HAD open dataset containing measurements of 12 classes from 14 people. Apart from the widely used accelerometer data it also provides gyro signals which we use in just the same way. The method also exploits a hierarchy of the classes and trains multiple individual classifiers in its nodes. Since the data consists of the measurements for multiple people, in our experiments we run cross-validation with a single fold per each person. In every iteration we also run an internal cross-validation to fit hyperparameter. As a result, the algorithm achieves the performance of 0.92 in terms of the mean F-measure. The experiments also show that the mixture of the three models is more stable than each of its components and achieves higher performance. Finally, the method proves to be significantly better than standard L 2-regularized Logistic Regression built up on the same feature set.
Karasikov M.E., Maximov Y.V. Dimensionality reduction for multi-class learning problems reduced to multiple binary problems // Machine Learning and Data Analysis. 2014. V. 1, Ōä¢ 9. Pp. 1273 - 1290. Modern machine learning problems, such as image classification, video recognition, text retrieval or engineering diagnostics, leads to the analysis of multi-class learning methods for high-dimensional datasets which can not be solved without data pre-processing. Principal Component Analysis and its randomized versions are some of the most widespread dimensionality reduction methods. We analyze the classification performance of various approaches to multi-class classification (One-vs-One, One-vs-All, Error-Correcting Output Codes) in combination with the dimensionality reduction based on Random Gaussian Projections. Computational efficiency of the Random Projections distinguishes it from other dimensionality reduction methods. With that, low-distortion property of this mapping allows to reduce dimensionality thrice and more with imperceptible quality losses. This leads to an effective and computationally cheap approach for solving multi-class problems in high-dimensional space. Basic theoretical foundations of the approach as well as its computational complexity analysis are discussed. Numerical stability and quality of the method proposed is supported by empirical evaluation of the approach. We provide a number of experiments for different machine learning methods over various real datasets from the open-source machine learning repositories. Experiments show applicability of Random Projections for cheap selection of the most suitable classifier, its parameters optimization and multi-class classification approach selection.
Mestetskiy L.M. Medial width of a ą░čłgure - an image shape descriptor // Machine Learning and Data Analysis. 2014. V. 1, Ōä¢ 9. Pp. 1291 - 1318. The problem of features generation for classification of flexible objects of variable shape, for example as a human figure or an animal figure, is to build shape descriptors which remain invariant during deformation of objects. The paper proposes the concept of building such integral figure shape descriptor called the function of the medial width. The concept of the medial width function we define on the basis of the skeleton and the radial function of the figure. Skeleton of figure is a set of points centers of circles inscribed in the figure. Radial function of figure is defined at the skeleton point and equal to the radius of the inscribed circle centered at that point. By definition, the medial width in skeleton points is equal to the radial function. We introduce the concept of the medial width in each of points in figure. The medial width the point of the figure is defined as the maximum length of the radius of an inscribed circle passing through the point. We then define the figure subset of a given width, consisting of all the points of the figure which medial width do not exceed the given value. After that, we define the medial width function of the figure - the area of subsets of a given width as a function of the width parameter. Thus, the medial width function is a width distribution function of the figure. The paper proposes an efficient algorithm to compute the medial width function for polygonal figures. The algorithm is based on the construction of the Voronoi diagram of line segments forming the boundary of the figure. The solution is generalized for the so-called circular figure obtained by replacing the corners of a polygonal figure with conjugate circular arcs. Choice of class of circular figures is caused by that they can approximate complex forms of objects in image. Efficiency and effectiveness of the proposed approach is demonstrated by the example of the computational experiments with the problem of palm shapes comparison for biometric identification.
Belozerov B.V., Bochkov A.S., Ushmaev O.S., Fuks O.M. Application of nearest neighbour method for sedimentation environment study // Machine Learning and Data Analysis. 2014. V. 1, Ōä¢ 9. Pp. 1319 - 1329. Distribution properties of sedimentary rocks determine considerably the geometry and size of the reservoir and consequently - the volume of hydrocarbon reserves. Therefore knowledge about general patterns of sedimentation rock formation is of crucial practical importance. This work offers the method to study the geological structure of oil field by automated recognition of litho-facial environment on basis of geophysical field data. In the work the spectral method is used in geophysical field representation, which is well-known for its effective application to the simulation of low-permeability and high-splitted reservoirs in the non-steady and anisotropic conditions. The input data are geophysical data interpreted by the filed geologist, which then form the training set for the machine learning algorithm. To reduce the dimensionality of the data only their significant features (Fourier coefficients) are retained in the learning step of the algorithm. Further the data are classified into the different facial regions using the machine learning technique. The method was tested on the real field and with the electrometric well data as the input it allowed to classify the wells according to the litho-facial sedimentation environment. In the article the method of facial environment reconstruction is described and its applicability to the real field is shown.
Vol. 1, Ōä¢10, 2014
Mandrikova O.V., Zhizhikina E.A. Estimation of degree of the geomagnetic field disturbance based on the combined use of wavelet transform with radial neural networks // Machine Learning and Data Analysis. 2014. V. 1, Ōä¢ 10. Pp. 1335 - 1344. The present paper is focused on the development of theoretical tools and software for the analysis of the geomagnetic field parameters and for the estimation of the geomagnetic field condition using modern methods of pattern recognition and digital signal processing. Existing methods for the geomagnetic data analysis do not allow to identify some regularities in the data and lead to the loss of important information. A method based on the combined use of the wavelet transform and radial neural networks has been proposed. This method allows to study subtle structural features of the geomagnetic data and to extract informative components which characterize the disturbance degree of the geomagnetic field. In the present paper, geomagnetic data structure was studied in detail, the signs of the geomagnetic activity increasing were defined and classes for the radial layer of the neural network were offered. Furthermore, a way of forming a radial layer was proposed. This way allows to significantly reduce the number of examples and to improve the quality of the geomagnetic data classification. On the basis of combination of decisions of the developed neural networks, a decision rule to estimate the geomagnetic field condition in the automatic mode has been suggested. The method has been successfully tested on the geomagnetic data that were kindly provided to the authors by the Institute of Cosmophysical Research and Radio Wave Propagation (Paratunka, Kamchatka Region, Russia). Using the proposed method in combination with other methods and approaches allows to enhance the quality of geomagnetic data automatic processing during space weather forecast.
Gornov A.Yu., Zarodnyuk T.S. Computing technology for estimation of convexity degree of the multiextremal function // Machine Learning and Data Analysis. 2014. V. 1, Ōä¢ 10. Pp. 1345 - 1353. Background: Optimization problems arise in the application of mathematical modeling method. Advance in applying of mathematical modeling depends on how successfully the researcher can construct a valid model and, primarily, on the convexity or nonconvexity of the involved functions. It can be argued that the class of convex functions mathematically well studied. However, the situation greatly changes in case of nonconvex problems. Methods and solutions: This paper proposes a technique of determining the degree of the function convexity, based on its stochastic approximation for the considerable area. The main idea of the approach is the pointwise study of the function convexity on the stochastic selected areas and systematization of this information to obtain an integrated estimate of convexity. The effectiveness of the proposed technology is demonstrated on a number of model examples of small dimensions, which are constructed and visualised areas of convexity. Conclusions: We can produce the selection of functional, used in the mathematical modeling, in order to choose more convenient for optimization analysis with the application of the proposed computing technology. This technique allows us to demonstrate "the areas of convexity-nonconvexity" for problems of small dimensions. The algorithm can be easily parallelized. The efficiency of the considered approach is investigated on a number of test and model problems. The obtained numerical results allow to expect for the creation of a new computational software, useful in solving practical problems in various scientific and technical fields.
Zhukova K.V., ReyerI.A. Skeleton base connectivity and parametric shape descriptor // Machine Learning and Data Analysis. 2014. V. 1, Ōä¢ 10. Pp. 1354 - 1368. In this paper a skeleton base connectivity is described. A skeleton base is a stable shape representation constructed with use of a polygonal figure approximating the shape. The change of a skeleton base with growth of the approximation accuracy value is modeled by erasing of edges of the skeleton by pairs of curves. The composition and location of erasing curves is defined by the boundary elements generating an edge, a certain subset of convex boundary vertices, and the accuracy value. A skeleton markup is a set of points of skeleton corresponding to essential changes of the skeleton base's structure. A skeleton markup defines a marked skeleton, in which every edge is erased by a unique pair moving in one direction. A skeleton markup may have points where the skeleton base's connectivity changes. Monotonic and continuous change of a skeleton base allows one to examine the family of skeleton bases and construct a variously detailed boundary-skeleton shape model. An analysis of this family allows us to calculate significance estimations for curvature features generated by convex vertices of the polygon's boundary. The set of convex vertices with their significance estimations is used as a shape descriptor. In the paper a generalization of the procedure of curvature features significance estimation for cases of changes of skeleton base's connectivity is proposed.
Chernousov V.O., Savchenko A.V. A Noise-Resistant Morphological Algorithm of Video-Based Moving Forklift Truck Detection // Machine Learning and Data Analysis. 2014. V. 1, Ōä¢ 10. Pp. 1369 - 1381. Background: The problem of video-based detection of the moving forklift truck is explored. It is shown that the detection quality of the state-of-the-art local descriptors (SURF, SIFT, FAST, ORB) is not satisfactory if the resolution is low and the lighting is changed dramatically. Methods: In this paper we propose to use a simple mathematical morphological algorithm to detect the presence of a cargo on the forklift truck. At first, the movement direction is estimated by the updating motion history image method and the front part of the moving object is obtained. Next, contours are detected and binary morphological operations in front of the moving object are used to estimate simple geometric features of empty forklift. Results: Our experimental study shows that the best results are achieved if the bounding rectangles of empty forklift contours are used as an object validation rule. Namely, FAR and FRR of empty cargo detection is 7% and 50% lower than FAR and FRR of the FAST descriptor. The proposed method is much more resistant to the effect of additive noise. The average frame processing time for our morphological algorithm is 5 ms (compare with 35 ms of FAST method). Conclusions: The proposed morphological method is task specific and can be used only for forklift truck detection. Additional detection principles need to be added to adopt algorithm for other moving object detection in noisy environment.
Makarov V.L., Beklaryan L.A., Belousov F.A. Steady regimens in Henning model and its modifications // Machine Learning and Data Analysis. 2014. V. 1, Ōä¢ 10. Pp. 1382 - 1395. Background: This paper is based on work of Peter A. Henning published in Lecture Notes in Economics and Mathematical Systems, 2008. In his model Henning explores an effect of death of populations owing to intrinsic causes. This subject is interesting to study, since such phenomenons may be observed as in unexplored wilderness and in human civilization. Degree of survival of population depends mainly on level of aggression between agents in this population. There are many papers on inter-specific aggression. In particular, it was considered in one of modifications of well known Sugar model. One can highlight another paper of S.Younger, in which inter-specific aggression and, in particular, revenge are also considered. Other works studying positive inter-specific influence may also be mentioned. For example there are papers where populations with altruistic agents are considered. These questions are studied by S. Bowles and E. Blume. Methods: This paper consists of two parts. The first one is dedicated to consideration of Henning model and its modifcations. In modifications of the model we are trying to overcome some disadvantages which initial Henning model has. In particular such factors as revenage and asymmetry are considered. In the second part the same questions are considered by using another model, construction of which differs significantly from Henning model and to a greater extent it is similar to already mentioned Sugar model. Results: The main distinction of the second model from the first one is endogeneity of behavior rules between agents. In other words if in Henning model and its modifications rules of interaction between agents are determined randomly, in the second model these interaction rules are determined based on conditions of agents and conditions of environment. Conclusions: In modifications of Henning model factors of revenage and asymmetry are studied. It was shown, that if these factors are not included in the model, then death of population is not observed. In the second part, where behavior between agents is determined endogeneously, many other interesting regularities are found.
Pokrovskaya I.V., Goldovskaya M.D., Dorofeyuk J.A., Kiseleva N.E. Intellectual methods of processing qualitative data // Machine Learning and Data Analysis. 2014. V. 1, Ōä¢ 10. Pp. 1396 - 1406. Intellectual processing of qualitative data problem is investigated. Two examples of the states of the problems and algorithms for qualitative data processing, presented in the form of the equity-type characteristics and the large dimension empirical graphs, are considered. The methodology of data mining (group) characteristics of equity-type (equivalent blurred classifications) is developed, this method was tested on real data. The possibilities of the exact and approximate representation of the large dimension graph through its description are studied. The optimization approach to the construction of the fuzzy classification is distributed to the problem of aggregation. In the framework of the structural-classification mining methodology of complex data the original information processing algorithms by large dimension graphs aggregation methods are developed.
Gusev V.D., Miroshnichenko L.A., SalomatinaN.V. Structural analogies in symbolic sequences of different nature // Machine Learning and Data Analysis. 2014. V. 1, Ōä¢ 10. Pp. 1407 - 1422. Symbolic sequences (words, strings, texts) as an object of study are encountered in various areas of knowledge: informatics, biology, linguistics, music. The notion of integrated repeats as elementary structure-forming units is general on conceptual level for all symbolic sequences, despite of diversity of alphabets, lengths and nature of the texts. The purpose of this work is the systematization of elementary repeats and their combinations, i.e. structural units of higher level. Their function in different language systems is discussed. Too low complexity of fragments of the text is usually correlated with existence of too long repeats or their high concentration. Thus a basis of all methods of research is a complexity profile construction and the analysis of complexity decomposition of the text in the sliding window mode. Such analysis gives a conception of the most typical structural units which can be found in texts. In the natural language texts, where repeatability is less expressed, also the profile of clustering can be used. DNA sequences of different organisms, texts in a natural language, and also neume himns are a source material for investigation. Systematization of structural units is the result of the complexity analysis of a huge number of texts of various nature. The interlanguage community principle is a cause for selection of the illustrating structures. The approach stated in this work and the algorithms realizing it have rather universal character in respect of its applicability to various language systems. The inter language analogies described at the level of structures can extend to formulation of substantial problems and selection of tools of their solving.
Dorofeyuk J.A., Pokrovskaya I.V., Kiseleva N.E. The complicated data mining algorithms complex in the study of weakly formalized management systems // Machine Learning and Data Analysis. 2014. V. 1, Ōä¢ 10. Pp. 1423 - 1438. The problem of the large-scale management system study is considered. The system consists of a large number of objects, each of which is characterized by a heterogeneous set of parameters. To solve the set of problems in this paper it is proposed to investigate the structure of the relative location of these objects in the informative parameters space. This allows to significantly increase the analysis efficiency of the system functioning and the stability of the procedures for making management decisions. To identify such patterns special mining complicated data algorithms complex and expert correction procedures were designed. The theoretical analysis of various types of SCDA algorithm was carried out, the algorithm convergence to the local extremum of the appropriate quality criterion theorems were proved.
Volkov Yu.S., Miroshnichenko V.L., Salienko A.E. Mathematical modeling of hill diagram for Kaplan turbine // Machine Learning and Data Analysis. 2014. V. 1, Ōä¢ 10. Pp. 1439 - 1450. Background: The problem of constructing of a hill diagram for the Kaplan turbine wheel based on the power test results of the model turbine is considered. The hill diagram is the basic document for selection of full-scale hydraulic turbine parameters (turbine wheel diameter, rotating frequency, etc.) that ensure the most efficient perfomance of the turbine at all modes of its operation in a particular hydropower station. Methods: Building a description of the mathematical formalism applied to mathematical modeling of the hill diagram of the Kaplan turbine based on the power test results of the model turbine. Results: The basis of the proposed approach is the approximation methods for multidimensional functions at scattered data. The methods are modifications and generalizations of DMM-splines and Hardy's multiquadrics. An example of modeling for real data on the basis of the program complex is given. Conclusions: The software package for mathematical modelling of hill diagram for the Kaplan turbine was created. In the future it is planned to use this software package for main full-scale hydraulic turbine parameters selection in a hydropower station.
Glinsky B.M., Marchenko M.A., Rodionov A.S., Karavaev D.A., Podkorytov D.I.Mappings of parallel algorithms on supercomputers with exaflops performance on the basis of simulation // Machine Learning and Data Analysis. 2014. V. 1, Ōä¢ 10. Pp. 1451 - 1465. The main objective of this research is a possibility of representation of parallel algorithms on different architectures of exaflops supercomputers based on simulation. The authors have proposed AGent NEtwork Simulator(AGNES) for investigating the scalability of algorithms and program software on admissible architectures of exaflops supercomputers. In this paper, the results of the simulation of different class algorithms are presented. These are algorithms of the forward statistical modeling and grid method. The problem of investigating the properties of scalability of parallel algorithms for implementing them on supercomputers of the future with exaflops performance goes beyond the scope of technological problems. In this paper, the authors show that it is possible to estimate the behavior of algorithms and to develop a modified computation scheme by implementing them on a simulation model. The imitating model allows one to identify the bottlenecks in algorithms and to find out how to modify an algorithm and what parameters need to be configured to scale this algorithm to a greater amount of cores. In the ICMMG, the simulation system AGNES has been developed, which was used for studying the scalability of distributed statistical modeling and for solving the problem of numerical 3D modeling of seismic wave propagation. Real calculations have shown that Monte Carlo method is linearly parallelized up to 1,000 computing cores. The behavior of the method proposed was investigated with simulation up to 500,000 cores. The dependence of parallelization on the number of collector cores was shown and the modified computing scheme for a great number of cores was proposed. For the other problem, a good compliance between experimental and model results up to 32768 cores is shown. The results were obtained on the simulation model for 1,124,864 cores. The calculations were performed on clusters of The Siberian Supercomputer Center.
