Vol. 1, Ōä¢5, 2013
Vasileisky A.S., Karatsuba E.A., Karelov A.I., Kuznetsov M.P., Reyer I.A. The algorithm of persistent scatterers movement detection on the satellite radar images of the earth surface // Machine Learning and Data Analysis. 2013. V. 1, Ōä¢ 5. Pp. 489-504. We describe a set of radar signal persistent scatterers with a metrics configuration of their mutual location and with their heights vector. Using the set of metrics configuration we detect movement of subset of the persistent scatterers concerning the whole set. We propose an algorithm of the set of metrics configuration construction using noisy satellite images of the earth surface and an algorithm of the persistent scatterers relations detection. We propose a method of the persistent scatterers movement detection and analyze its properties. The method is illustrated by the synthetic and real data.
Valkov A.S., Kozhanov E.M., Motrenko A.P., Husainov F.I. Constructing a cross-correlation model to forecast the utilization of a railway junction station // Machine Learning and Data Analysis. 2013. V. 1, Ōä¢ 5. Pp. 505-518. The problem of detecting causal relationships between time series is studied. The authors propose a forecasting model that considers detected relationships. The model is aimed to forecast the utilization of a railway junction station. The model relies on the history of a junction station utilization as well as on the time series for the main financial instruments and regulations. Expert's assessments are used to construct the model. A method that evaluates plausibility of the expert's assessments is proposed. The method is illustrated with the Russian Railways data.
The paper extends the approach towards morphological analysis of unknown Russian surnames, which has been implemented as part of the ISIDA-T information extraction software. The idea is first to construct a redundant set of hypotheses and then to reduce the number of hypotheses using various heuristic techniques like ruling out impossible options with filtering rules; clustering textual forms and filtering hypotheses within clusters; preference-based ranking of options. Some limitations of the method are analysed, including those due to its deterministic nature.
Nedelko V.M. Investigation of accuracy of crossvalidation // Machine Learning and Data Analysis. 2013. V. 1, Ōä¢ 5. Pp. 526-533. Several kinds of cross-validation, such as leave-one-out and K-fold cross-validaton, and also an empirical risk based bias adjusted estimate are investigated. The accuracies of the estimates on synthetic data are compared using FisherŌĆÖs discriminant and histogram classifier. All estimates under consideration have shown similar accuracy.
Pushnyakov A.S. Recognition of printed image using spectral transform // Machine Learning and Data Analysis. 2013. V. 1, Ōä¢ 5. Pp. 534-541. This paper is about a problem of classification real and printed eye-image. A spectral transform of image is used. We proposed to nd a periodical structure that generates high frequency spectral magnitude. A feature space is based on radial component of the Fourier image. The problem of classification is solved by metric classifier.
Mnukhin V.B. Digital images on a complex discrete torus // Machine Learning and Data Analysis. 2013. V. 1, Ōä¢ 5. Pp. 542-551. An algebraic method for digital images analysis and processing is considered. It is based on the presentation of digital images of size 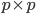 , where
, where 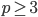 is the prime number such that
is the prime number such that 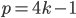 , as functions on a complex discrete torus. For such images, complex rotations are introduced and a new invertible linear transform, called the modular Mellin transform, is presented. The discrete modular Fourier-Mellin transform, invariant under circular shifts, scaling, and complex rotations, is also defined.
, as functions on a complex discrete torus. For such images, complex rotations are introduced and a new invertible linear transform, called the modular Mellin transform, is presented. The discrete modular Fourier-Mellin transform, invariant under circular shifts, scaling, and complex rotations, is also defined.
Prokasheva O.V. Eficiency improvement of the FCA-based classi cation algorythm // Machine Learning and Data Analysis. 2013. V. 1, Ōä¢ 5. Pp. 552-558. In this paper we investigate the FCA classi cation algorithm on the basis of minimal hypothesis. The algorithm is tested on various benchmarks with nominal and real features. Also various modifications of the algorithm are presented and compared in terms of their eficiency. These modifications are aimed to reduce classification errors and refusals by using various metrics and voting procedures.
Fedotov N.G., Goldueva D.A. Analysis of three-dimensional textures from a position of stochastic geometry and functional analysis // Machine Learning and Data Analysis. 2013. V. 1, Ōä¢ 5. Pp. 559-567. A new approach is suggested on three-dimensional (3D) texture analysis based on stochastic geometry and functional analysis. A sensivity of triple features to scale transformation was examined on 3D textures scanned by the atomic-force microscope.
D'yakonov A. Data mining problems solving using linear combinations of deformations // Machine Learning and Data Analysis. 2013. V. 1, Ōä¢ 5. Pp. 568-579. A review of some theoretical results on function representation by linear combination of <> of linear functions is presented. The results are started from Kolmogorov's papers on interpolation and Zhuravlev's papers on algebraic approach. It is shown that the idea of such representation can be useful in practice. Some solutions of real problems from international data mining competitions are described.
Yankovskaya A.E., Kitler S.V. Intelligent Analysis of Data and Knowledge for Stenting of Coronary Artery// Machine Learning and Data Analysis. 2013. V. 1, Ōä¢ 5. Pp. 580-589. The paper is devoted to intelligent analysis of data and knowledge for stenting of coronary artery. The basic stages of the intelligent analysis of data and knowledge for stenting of coronary artery are described. An approach for analysis of data and knowledge for stenting of coronary artery is presented. Software realization of the approach is implemented in the intelligent system. Theintelligent system is developed as dynamical plug-ins in the intelligent instrumental software (IIS) IMSLOG. The applied intelligent systems are constructing on the base of the IIS IMSLOG. Aprobation results of the intelligent system is given.
Chinaev N.N., Matveev I.A. Precise pupil border locating // Machine Learning and Data Analysis. 2013. V. 1, Ōä¢ 5. Pp. 590-597. Method of locating precise pupil border in monochrome images of eye is proposed. The method is based on image binarisation followed by detection of pupil as one of the connected components. Pupil border is estimated as a boundary or part of the boundary of the connected component. Hough transform is employed to separate pupil in case of its merging to one component with other objects and to verify the plausibility of the detection. Statistical results illustrating performance of the method are presented. Images from public domain database were used for tests.
Teklina L.G., Kotel'nikov I.V., S G.I. Application of the pattern recognition methods for the synthesis of a piecewise-linear systems of the quasi-invariant control // Machine Learning and Data Analysis. 2013. V. 1, Ōä¢ 5. Pp. 598-605. The work is devoted to the further development of a new approach to the synthesis of the quasi-invariant control systems. This approach is based on the formulation and solution of the synthesis problem using methods of pattern recognition with an active experiment. Extension of a new method of synthesis for the linear systems to the field of nonlinear control systems is related with overcoming the major drawback of linear systems: large values of a control function in the transition process.
Dvoenko S., Pshenichny D. On metric correction of matrices of pairwise comparisons // Machine Learning and Data Analysis. 2013. V. 1, Ōä¢ 5. Pp. 606-620. In machine learning and data mining the experimental results are often immediately represented as matrices of pairwise comparisons between a set elements. The condition of the correct immersion of the given set of objects into a metric space is a nonnegative definiteness of the pairwise similarity matrix. In this case, similarities are interpreted as scalar products and dissimilarities - as distances respectively. In this paper, the metric violation conditions are under investigation. The approach to correct metric violations in pairwise comparison matrices is developed based on idea to minimize distortions of some its elements.
Karkishchenko A.N., Mnukhin V.B. Recovery of points symmetry in images of objects with reflectional symmetry // Machine Learning and Data Analysis. 2013. V. 1, Ōä¢ 5. Pp. 621-631. In this work, we consider the problem to obtain more accurate information about location of points based on a priori knowledge of their symmetries. Methods to solve this symmetrization problem with respect to vertical and inclined axes of reflectional symmetry are considered jointly with the more general case of reflectional symmetry with respect to an indefinite reflection axis. The methods produce the minimal deformation that enhances approximate symmetries present in a given arrangement of points.
Chuvilin K.V. The use of rules with complex structure for LaTeX documents correction // Machine Learning and Data Analysis. 2013. V. 1, Ōä¢ 5. Pp. 632-640. The problem of automatic synthesis of LATEX documents editing rules is investigated. Each document is represented as a parse tree. Tree nodes mappings of initial documents to edited documents form the training set, which is used to generate the rules. Simple rules that implement removal, insertion, or replacing operations of single node and use linear sequence of vertices to select a position are synthesized primarily. The constructed rules are grouped based on the positions of applicability and quality. The rules that use tree-like structure of nodes to select the position are studied. The changes in the quality of the rules during the sequental increase of training dcocuments set are analized.
Razin N.A., Chernousova E.O., Krasotkina O.V., Mottl V.V. Elastic-Net Relevance Vector Machines for selective multimodal regression estimation // Machine Learning and Data Analysis. 2013. V. 1, Ōä¢ 5. Pp. 641-653. We address the problem of regression estimation under the assumption that pair-wise comparison of objects is arbitrarily scored by real numbers. Such a linear embedding is much more general than the traditional kernel-based approach, which demands positive semi-definiteness of the matrix of object comparisons. This demand is frequently prohibitive and is further complicated if there exist a large number of comparison functions, i.e., multiple modalities of object representation. In these cases, the experimenter typically also has the problem of eliminating redundant modalities and objects. In the context of the general pair-wise comparison space this problem becomes mathematically analogous to that of wrapper-based feature selection. The resulting convex training criterion based on the principle of Elastic Net regression estimation is analogous to Tipping's Regression Relevance Vector Machine, but essentially generalizes it via the presence of a structural parameter controlling the selectivity level.
Vol. 1, Ōä¢6, 2013
Vorontsov K.V., Potapenko A.A. EM-like algorithms for probabilistic topic modeling // Machine learning and data analysis. 2013. V. 1, Ōä¢ 6. Pp. 657-686. Probabilistic topic models discover a low-dimensional interpretable representation of text cor-pora by estimating a multinomial distribution over topics for each document and a multinomial distribution over terms for each topic. We consider a unified family of EM-like algorithms with smoothing, sampling, sparsing, and robustness heuristics that can be used in any combinations.Known models PLSA, LDA, SWB (special words with background), as well as new ones can be considered as special cases of the presented broad family of models. We propose a new simple ro-bust algorithm suitable for sparse models that do not require to estimate and store a big matrix of noise parameters. We find experimentally optimal combinations of heuristics with sparsing strategies and discover than sparse robust model without Dirichlet smoothing performs very well and gives more than 99% of zeros in multinomial distributions without loss of perplexity.
Manilo L.A., Nemirko A.P., Salamonova I.S. Automatic analysis of form of spirographic loops on their signatures // Machine learning and data analysis. 2013. V. 1, Ōä¢ 6. Pp. 687-694. The analysis of various numerical characteristics of loops <> obtained from a signature of two-dimensional curves is carried out. Possibilities of application of the dynamic analysis of spirograms for an assessment of parameters of ventilation of lungs and early diag-nostics of pathologies are shown. Methods of the automatic analysis of loops in the conditions of mechanical ventilation are considered.
Chuvilina E.V. Informative features for diagnostics of bearings by detection of local inhomogeneities // Machine learning and data analysis. 2013. V. 1, Ōä¢ 6. Pp. 695-704. The task of diagnostics of bearings in a gasturbine engine is seen as a pattern recognition problem based on the detection of local inhomogeneities in the vibrosignal. Proposed and investigated a number of features, allocated most informative ones having a linear separability, namely: fractal dimension, drift vector, matrix of dependence increments from the signal.
Djukova E.V., Lyubimtseva M.M., Prokofjev P.A. Algebraic-logical correction in recognition problems // Machine learning and data analysis. 2013. V. 1, Ōä¢ 6. Pp. 705-713.A problem of constructing for the correct recognition algorithms based on incorrect elementary classi ers (EC) is considered. A new type of correct sets of EC is suggested that called anti-monotonic. A new model of correct recognition algorithms based on antimonotonic correct sets of EC is constructed. This model is tested on the real tasks.
Kudinov M.S. Shallow parsing of Russian text with conditional random fields // Machine learning and data analysis. 2013. V. 1, Ōä¢ 6. Pp. 714-724. The paper describes an aproach to chunking of sentence in Russian. Arguments in favor of the correctness and practicability of the chunking problem for a language with free word order are provided. An aproach based on conditional random fields provides detection of a certain class of chunks (base-NPs) with F1 measure above .94 and the training set may be obtained from the raw text data processed by statistical parser without manual post-processing. Meanwhile, detecting longer phrases remains problematic and the F1 measure in the corresponding experiment is relatively small.
Lange M.M., Ganebnykh S.N. Hierarchical Data Structures and Decision Algorithms for Efficient Image Classification // Machine Learning and Data Analysis. 2013. V. 1, Ōä¢ 6. Pp. 725-733. The problem of image-based object recognition in terms of computational complexity as a function of error rate is studied. Using a multilevel network of the template objects, two fast guided search algorithms for the decision template are suggested. For the guided search and exhaustive search algorithms, comparative estimations of computational complexity are estimated. Experimental curves of computational complexity as the function of classification error rate are obtained for a common source of gestures, signatures and faces using the guided and exhaustive search decision algorithms.
Vorontsov K.V., Frey A.I., Sokolov E.A. Computable combinatorial overfitting bounds // Machine learning and data analysis. 2013. V. 1, Ōä¢ 6. Pp. 734-743. In this paper we study computable combinatorial data dependent generalization bounds. This approach is based on simplified probabilistic assumptions: we assume that the instance space is finite, the labeling function is deterministic, and the loss function is binary. We use a random walk across a set of linear classifiers with low error rate to compute the bound efficiently. We provide experimental evidence to confirm that this approach leads to practical overfitting bounds in classification tasks.
Razin N.A., Mottl V.V. Numerical Algorithms for Selective Multimodal Pattern Recognition // Machine learning and data analysis. 2013. V. 1, Ōä¢ 6. Pp. 744-760. We address the problem of regression estimation under the assumption that pair-wise compar-ison of objects is arbitrarily scored by real numbers. Such a linear embedding is much more general than the traditional kernel-based approach, which demands positive semi-definiteness of the matrix of object comparisons. The advantage of proposed algorithms is their good scala-bility at multiprocessor systems, leading to use powerful clusters for solving pattern recognition problems for large data. The resulting computational speed for algorithms tested on usual video card NVidia GeForce 310M is 25 times faster compared to naive algorithms implementation.
Frey A.I., Tolstikhin I.O. Combinatorial bounds on probability of overfitting based on clustering and coverage of classifiers. // Machine Learning and Data Analysis. 2013. V. 1, Ōä¢ 6. Pp. 761-778. The paper improves existing combinatorial bounds on probability of overfitting. A new bound is based on partitioning of a set of classifiers into non-overlapping clusters, and then embedding each cluster into a superset with known exact formula for the probability of overfitting. The key idea is to account for similarities between classifiers within each cluster. As a result, the new bound outperforms existing combinatorial bounds in our experiments on real datasets from UCI repository.
Murashov D.M., Berezin A.V., Ivanova Y.Yu. Composing feature description of paintings texture// Machine Learning and Data Analysis. 2013. V.1, Ōä¢ 6. Pp. 779-786.In this paper, a task of composing a feature description of texture of paintings for the purposes of attribution is considered. A feature description for comparing texture fragments based on ridges of grayscale image relief, structure tensor, and local wave number, is proposed. As compared to conventional techniques, the selected features are computed only in informative image fragments and do not require brush stroke segmentation. The results of computing experiments showed the efficiency of the proposed feature set. The feature set gives quantitative description of painter's artistic style and provide suitable accuracy of feature computing. The proposed feature set may be used as a part of techno-technological description of fine art paintings for attribution.
Khashin S.I. Dynamic segmentation of frames sequences// Machine Learning and Data Analysis. 2013. V.1, Ōä¢ 6. Pp. 787-795. Describes the image segmentation algorithm, based not on a single frame, but on the pair of frames from a video sequence. Compared with usual, static segmentation of each frame individually, the quality improves drastically. While maintaining the same error, the number of segments can be reduced in tens times. Typical number of segments needed to produce an acceptable error is reduced from  to
to 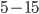 .
.
