–Δ. 1, ⳕ5, 2013
–£–Α―¹–Η–Μ–Β–Ι―¹–Κ–Η–Ι –ê.–Γ., –ö–Α―Ä–Α―Ü―É–±–Α –ï.–ê., –ö–Α―Ä–Β–Μ–Ψ–≤ –ê.–‰., –ö―É–Ζ–Ϋ–Β―Ü–Ψ–≤ –€.–ü., –†–Β–Ι–Β―Ä –‰.–ê. –û–±–Ϋ–Α―Ä―É–Ε–Β–Ϋ–Η–Β –¥–≤–Η–Ε–Β–Ϋ–Η―è ―É―¹―²–Ψ–Ι―΅–Η–≤―΄―Ö –Ψ―²―Ä–Α–Ε–Α―²–Β–Μ–Β–Ι –Ω–Ψ ―¹–Β―Ä–Η–Η ―¹–Ω―É―²–Ϋ–Η–Κ–Ψ–≤―΄―Ö ―Ä–Α–¥–Η–Ψ–Μ–Ψ–Κ–Α―Ü–Η–Ψ–Ϋ–Ϋ―΄―Ö ―¹–Ϋ–Η–Φ–Κ–Ψ–≤ –Ζ–Β–Φ–Ϋ–Ψ–Ι –Ω–Ψ–≤–Β―Ä―Ö–Ϋ–Ψ―¹―²–Η // –€–Α―à–Η–Ϋ–Ϋ–Ψ–Β –Ψ–±―É―΅–Β–Ϋ–Η–Β –Η –Α–Ϋ–Α–Μ–Η–Ζ –¥–Α–Ϋ–Ϋ―΄―Ö. 2013. T. 1, ⳕ 5. C. 489-504. –ù–Α–±–Ψ―Ä ―É―¹―²–Ψ–Ι―΅–Η–≤―΄―Ö –Ψ―²―Ä–Α–Ε–Α―²–Β–Μ–Β–Ι ―Ä–Α–¥–Η–Ψ–Μ–Ψ–Κ–Α―Ü–Η–Ψ–Ϋ–Ϋ–Ψ–≥–Ψ ―¹–Η–≥–Ϋ–Α–Μ–Α –Ψ–Ω–Η―¹–Α–Ϋ –Φ–Β―²―Ä–Η―΅–Β―¹–Κ–Ψ–Ι –Κ–Ψ–Ϋ―³–Η–≥―É―Ä–Α―Ü–Η–Β–Ι –Η―Ö –≤–Ζ–Α–Η–Φ–Ϋ–Ψ–≥–Ψ ―Ä–Α―¹–Ω–Ψ–Μ–Ψ–Ε–Β–Ϋ–Η―è –Η –≤–Β–Κ―²–Ψ―Ä–Ψ–Φ –Η―Ö ―É―¹–Μ–Ψ–≤–Ϋ―΄―Ö –≤―΄―¹–Ψ―². –ü–Ψ ―¹–Β―Ä–Η–Η –Φ–Β―²―Ä–Η―΅–Β―¹–Κ–Η―Ö –Κ–Ψ–Ϋ―³–Η–≥―É―Ä–Α―Ü–Η–Ι ―²―Ä–Β–±―É–Β―²―¹―è –Ψ–Ω―Ä–Β–¥–Β–Μ–Η―²―¨ –¥–≤–Η–Ε–Β–Ϋ–Η–Β –Ϋ–Β–Κ–Ψ―²–Ψ―Ä–Ψ–Ι ―΅–Α―¹―²–Η ―É―¹―²–Ψ–Ι―΅–Η–≤―΄―Ö –Ψ―²―Ä–Α–Ε–Α―²–Β–Μ–Β–Ι –Ψ―²–Ϋ–Ψ―¹–Η―²–Β–Μ―¨–Ϋ–Ψ –≤―¹–Β–≥–Ψ –Ϋ–Α–±–Ψ―Ä–Α. –£ ―Ä–Α–±–Ψ―²–Β –Ω―Ä–Β–¥–Μ–Ψ–Ε–Β–Ϋ –Α–Μ–≥–Ψ―Ä–Η―²–Φ –Ω–Ψ―¹―²―Ä–Ψ–Β–Ϋ–Η―è ―¹–Β―Ä–Η–Η –Φ–Β―²―Ä–Η―΅–Β―¹–Κ–Η―Ö –Κ–Ψ–Ϋ―³–Η–≥―É―Ä–Α―Ü–Η–Ι –Ω–Ψ –Ζ–Α―à―É–Φ–Μ–Β–Ϋ–Ϋ―΄–Φ –¥–Α–Ϋ–Ϋ―΄–Φ ―¹–Ψ ―¹–Ω―É―²–Ϋ–Η–Κ–Ψ–≤―΄―Ö ―¹–Ϋ–Η–Φ–Κ–Ψ–≤ –Ζ–Β–Φ–Ϋ–Ψ–Ι –Ω–Ψ–≤–Β―Ä―Ö–Ϋ–Ψ―¹―²–Η –Η –≤―΄―è–≤–Μ–Β–Ϋ–Η―è ―¹–≤―è–Ζ–Β–Ι –Φ–Β–Ε–¥―É ―É―¹―²–Ψ–Ι―΅–Η–≤―΄–Φ–Η –Ψ―²―Ä–Α–Ε–Α―²–Β–Μ―è–Φ–Η. –ü―Ä–Β–¥–Μ–Ψ–Ε–Β–Ϋ –Φ–Β―²–Ψ–¥ –Ψ–±–Ϋ–Α―Ä―É–Ε–Β–Ϋ–Η―è –¥–≤–Η–Ε–Β–Ϋ–Η―è –Ψ―²―Ä–Α–Ε–Α―²–Β–Μ–Β–Ι, –Η―¹―¹–Μ–Β–¥–Ψ–≤–Α–Ϋ―΄ –Β–≥–Ψ ―¹–≤–Ψ–Ι―¹―²–≤–Α. –€–Β―²–Ψ–¥ –Ω―Ä–Ψ–Η–Μ–Μ―é―¹―²―Ä–Η―Ä–Ψ–≤–Α–Ϋ ―¹–Η–Ϋ―²–Β―²–Η―΅–Β―¹–Κ–Η–Φ–Η –Η ―Ä–Β–Α–Μ―¨–Ϋ―΄–Φ–Η –¥–Α–Ϋ–Ϋ―΄–Φ–Η.
–£–Α–Μ―¨–Κ–Ψ–≤ –ê.–Γ., –ö–Ψ–Ε–Α–Ϋ–Ψ–≤ –ï.–€., –€–Ψ―²―Ä–Β–Ϋ–Κ–Ψ –ê.–ü., –Ξ―É―¹–Α–Η–Ϋ–Ψ–≤ –Λ.–‰. –ü–Ψ―¹―²―Ä–Ψ–Β–Ϋ–Η–Β –Κ―Ä–Ψ―¹―¹-–Κ–Ψ―Ä―Ä–Β–Μ―è―Ü–Η–Ψ–Ϋ–Ϋ―΄―Ö –Ζ–Α–≤–Η―¹–Η–Φ–Ψ―¹―²–Β–Ι –Ω―Ä–Η –Ω―Ä–Ψ–≥–Ϋ–Ψ–Ζ–Β –Ζ–Α–≥―Ä―É–Ε–Β–Ϋ–Ϋ–Ψ―¹―²–Η –Ε–Β–Μ–Β–Ζ–Ϋ–Ψ–¥–Ψ―Ä–Ψ–Ε–Ϋ–Ψ–≥–Ψ ―É–Ζ–Μ–Α // –€–Α―à–Η–Ϋ–Ϋ–Ψ–Β –Ψ–±―É―΅–Β–Ϋ–Η–Β –Η –Α–Ϋ–Α–Μ–Η–Ζ –¥–Α–Ϋ–Ϋ―΄―Ö. 2013. T. 1, ⳕ 5. C. 505-518. –†–Α―¹―¹–Φ–Α―²―Ä–Η–≤–Α–Β―²―¹―è –Ω―Ä–Ψ–±–Μ–Β–Φ–Α –Ψ–±–Ϋ–Α―Ä―É–Ε–Β–Ϋ–Η―è –Ω―Ä–Η―΅–Η–Ϋ–Ϋ–Ψ-―¹–Μ–Β–¥―¹―²–≤–Β–Ϋ–Ϋ―΄―Ö ―¹–≤―è–Ζ–Β–Ι –≤ ―Ä–Α–Ζ–Ϋ–Ψ―Ä–Ψ–¥–Ϋ―΄―Ö –≤―Ä–Β–Φ–Β–Ϋ–Ϋ―΄―Ö ―Ä―è–¥–Α―Ö. –ü―Ä–Β–¥–Μ–Α–≥–Α–Β―²―¹―è –Ω―Ä–Ψ–≥–Ϋ–Ψ―¹―²–Η―΅–Β―¹–Κ–Α―è –Φ–Ψ–¥–Β–Μ―¨, –Η―¹–Ω–Ψ–Μ―¨–Ζ―É―é―â–Α―è –≤―΄―è–≤–Μ–Β–Ϋ–Ϋ―΄–Β ―¹–≤―è–Ζ–Η. –€–Ψ–¥–Β–Μ―¨ –Ω―Ä–Β–¥–Ϋ–Α–Ζ–Ϋ–Α―΅–Β–Ϋ–Α –¥–Μ―è –Ω―Ä–Ψ–≥–Ϋ–Ψ–Ζ–Η―Ä–Ψ–≤–Α–Ϋ–Η―è –Ζ–Α–≥―Ä―É–Ε–Β–Ϋ–Ϋ–Ψ―¹―²–Η –Ε–Β–Μ–Β–Ζ–Ϋ–Ψ–¥–Ψ―Ä–Ψ–Ε–Ϋ–Ψ–≥–Ψ ―É–Ζ–Μ–Α. –€–Ψ–¥–Β–Μ―¨ –Η―¹–Ω–Ψ–Μ―¨–Ζ―É–Β―² –Κ–Α–Κ –Η―¹―²–Ψ―Ä–Η―΅–Β―¹–Κ–Η–Β –¥–Α–Ϋ–Ϋ―΄–Β –Ψ –Ζ–Α–≥―Ä―É–Ε–Β–Ϋ–Ϋ–Ψ―¹―²–Η, ―²–Α–Κ –Η –≤–Ϋ–Β―à–Ϋ–Η–Β –¥–Α–Ϋ–Ϋ―΄–Β: –±–Η―Ä–Ε–Β–≤―΄–Β ―Ü–Β–Ϋ―΄ –Ϋ–Α –Ψ―¹–Ϋ–Ψ–≤–Ϋ―΄–Β –Η–Ϋ―¹―²―Ä―É–Φ–Β–Ϋ―²―΄ –Η –Ϋ–Ψ―Ä–Φ–Α―²–Η–≤–Ϋ―΄–Β –¥–Ψ–Κ―É–Φ–Β–Ϋ―²―΄. –ü―Ä–Η –Ω–Ψ―¹―²―Ä–Ψ–Β–Ϋ–Η–Η –Φ–Ψ–¥–Β–Μ–Η –Η―¹–Ω–Ψ–Μ―¨–Ζ―É―é―²―¹―è ―ç–Κ―¹–Ω–Β―Ä―²–Ϋ―΄–Β –≤―΄―¹–Κ–Α–Ζ―΄–≤–Α–Ϋ–Η―è –Ψ―²–Ϋ–Ψ―¹–Η―²–Β–Μ―¨–Ϋ–Ψ –≤–Η–¥–Α ―¹–≤―è–Ζ–Β–Ι. –ü―Ä–Β–¥–Μ–Ψ–Ε–Β–Ϋ –Φ–Β―²–Ψ–¥ –Ψ―Ü–Β–Ϋ–Κ–Η –¥–Ψ―¹―²–Ψ–≤–Β―Ä–Ϋ–Ψ―¹―²–Η ―ç–Κ―¹–Ω–Β―Ä―²–Ϋ―΄―Ö –≤―΄―¹–Κ–Α–Ζ―΄–≤–Α–Ϋ–Η–Ι. –€–Β―²–Ψ–¥ –Ω―Ä–Ψ–Η–Μ–Μ―é―¹―²―Ä–Η―Ä–Ψ–≤–Α–Ϋ –¥–Α–Ϋ–Ϋ―΄–Φ–Η –≥―Ä―É–Ζ–Ψ–≤―΄―Ö –Ω–Β―Ä–Β–≤–Ψ–Ζ–Ψ–Κ –†–•–î.
–Γ―É–Μ–Β–Ι–Φ–Α–Ϋ–Ψ–≤–Α –ï., –ö–Ψ–Ϋ―¹―²–Α–Ϋ―²–Η–Ϋ–Ψ–≤ –ö. –û–± ―ç–≤―Ä–Η―¹―²–Η―΅–Β―¹–Κ–Ψ–Φ –Φ–Β―²–Ψ–¥–Β ―Ä–Α–Ζ―Ä–Β―à–Β–Ϋ–Η―è –Ϋ–Β–Ψ–¥–Ϋ–Ψ–Ζ–Ϋ–Α―΅–Ϋ–Ψ―¹―²–Η –Ω―Ä–Η –Φ–Ψ―Ä―³–Ψ–Μ–Ψ–≥–Η―΅–Β―¹–Κ–Ψ–Φ –Α–Ϋ–Α–Μ–Η–Ζ–Β –Ϋ–Β–Ζ–Ϋ–Α–Κ–Ψ–Φ―΄―Ö ―³–Α–Φ–Η–Μ–Η–Ι // –€–Α―à–Η–Ϋ–Ϋ–Ψ–Β –Ψ–±―É―΅–Β–Ϋ–Η–Β –Η –Α–Ϋ–Α–Μ–Η–Ζ –¥–Α–Ϋ–Ϋ―΄―Ö. 2013. T. 1, ⳕ 5. C. 519-525. –Γ―²–Α―²―¨―è –Ω–Ψ―¹–≤―è―â–Β–Ϋ–Α ―Ä–Α–Ζ–≤–Η―²–Η―é –Ω–Ψ–¥―Ö–Ψ–¥–Α –Κ –Φ–Ψ―Ä―³–Ψ–Μ–Ψ–≥–Η―΅–Β―¹–Κ–Ψ–Φ―É –Α–Ϋ–Α–Μ–Η–Ζ―É –Ϋ–Β–Ζ–Ϋ–Α–Κ–Ψ–Φ―΄―Ö ―³–Α–Φ–Η–Μ–Η–Ι –≤ ―Ä―É―¹―¹–Κ–Ψ―è–Ζ―΄―΅–Ϋ–Ψ–Φ ―²–Β–Κ―¹―²–Β, ―Ä–Β–Α–Μ–Η–Ζ–Ψ–≤–Α–Ϋ–Ϋ–Ψ–≥–Ψ –≤ ―¹–Ω–Β―Ü–Η–Α–Μ―¨–Ϋ–Ψ–Φ –Φ–Ψ–¥―É–Μ–Β ―¹–Η―¹―²–Β–Φ―΄ –Η–Ϋ―²–Β–Μ–Μ–Β–Κ―²―É–Α–Μ―¨–Ϋ–Ψ–≥–Ψ –Α–Ϋ–Α–Μ–Η–Ζ–Α ―²–Β–Κ―¹―²–Α –‰–Γ–‰–î–ê-–Δ. –‰–¥–Β―è –Ω–Ψ–¥―Ö–Ψ–¥–Α ―¹–Ψ―¹―²–Ψ–Η―² –≤ –Ω–Β―Ä–≤–Ψ–Ϋ–Α―΅–Α–Μ―¨–Ϋ–Ψ–Φ –Ω–Ψ―¹―²―Ä–Ψ–Β–Ϋ–Η–Η –Ζ–Α–≤–Β–¥–Ψ–Φ–Ψ –Η–Ζ–±―΄―²–Ψ―΅–Ϋ–Ψ–≥–Ψ –Φ–Ϋ–Ψ–Ε–Β―¹―²–≤–Α –≤–Α―Ä–Η–Α–Ϋ―²–Ψ–≤ - –≥–Η–Ω–Ψ―²–Β–Ζ –Η –Ω–Ψ―¹–Μ–Β–¥―É―é―â–Β–Φ ―¹–Ψ–Κ―Ä–Α―â–Β–Ϋ–Η–Η ―΅–Η―¹–Μ–Α –≤–Α―Ä–Η–Α–Ϋ―²–Ψ–≤ ―¹ –Ω–Ψ–Φ–Ψ―â―¨―é ―Ä–Α–Ζ–Μ–Η―΅–Ϋ―΄―Ö ―ç–≤―Ä–Η―¹―²–Η―΅–Β―¹–Κ–Η―Ö –Φ–Β―²–Ψ–¥–Ψ–≤: –Η―¹–Κ–Μ―é―΅–Β–Ϋ–Η–Β –Ϋ–Β–≤–Ψ–Ζ–Φ–Ψ–Ε–Ϋ―΄―Ö –≤–Α―Ä–Η–Α–Ϋ―²–Ψ–≤ –Ϋ–Α –Ψ―¹–Ϋ–Ψ–≤–Α–Ϋ–Η–Η –¥–Ψ–Ω–Ψ–Μ–Ϋ–Η―²–Β–Μ―¨–Ϋ―΄―Ö –Ω―Ä–Ψ–≤–Β―Ä–Ψ–Κ –Ω―Ä–Α–≤–Η–Μ–Α–Φ–Η-―³–Η–Μ―¨―²―Ä–Α–Φ–Η; –Κ–Μ–Α―¹―²–Β―Ä–Η–Ζ–Α―Ü–Η―è ―¹–Μ–Ψ–≤–Ψ―³–Ψ―Ä–Φ –Η ―³–Η–Μ―¨―²―Ä–Α―Ü–Η―è ―Ä–Β–Ζ―É–Μ―¨―²–Α―²–Ψ–≤ –≤–Ϋ―É―²―Ä–Η –Κ–Μ–Α―¹―²–Β―Ä–Α; ―Ä–Α–Ϋ–Ε–Η―Ä–Ψ–≤–Α–Ϋ–Η–Β –≤–Α―Ä–Η–Α–Ϋ―²–Ψ–≤ –Ω–Ψ –Ω―Ä–Β–¥–Ω–Ψ―΅―²–Η―²–Β–Μ―¨–Ϋ–Ψ―¹―²–Η. –ê–Ϋ–Α–Μ–Η–Ζ–Η―Ä―É―é―²―¹―è –Ψ–≥―Ä–Α–Ϋ–Η―΅–Β–Ϋ–Η―è –Ϋ–Α –≤–Ψ–Ζ–Φ–Ψ–Ε–Ϋ–Ψ―¹―²–Η –Φ–Β―²–Ψ–¥–Α, –≤―΄―²–Β–Κ–Α―é―â–Η–Β, –≤ ―΅–Α―¹―²–Ϋ–Ψ―¹―²–Η, –Η–Ζ –Β–≥–Ψ –¥–Β―²–Β―Ä–Φ–Η–Ϋ–Η―Ä–Ψ–≤–Α–Ϋ–Ϋ–Ψ–Ι –Ω―Ä–Η―Ä–Ψ–¥―΄.
–ù–Β–¥–Β–Μ―¨–Κ–Ψ –£. –‰―¹―¹–Μ–Β–¥–Ψ–≤–Α–Ϋ–Η–Β –Ω–Ψ–≥―Ä–Β―à–Ϋ–Ψ―¹―²–Η –Ψ―Ü–Β–Ϋ–Ψ–Κ ―¹–Κ–Ψ–Μ―¨–Ζ―è―â–Β–≥–Ψ ―ç–Κ–Ζ–Α–Φ–Β–Ϋ–Α // –€–Α―à–Η–Ϋ–Ϋ–Ψ–Β –Ψ–±―É―΅–Β–Ϋ–Η–Β –Η –Α–Ϋ–Α–Μ–Η–Ζ –¥–Α–Ϋ–Ϋ―΄―Ö. 2013. T. 1, ⳕ 5. C. 526-533.–£ ―Ä–Α–±–Ψ―²–Β –Ϋ–Α –Φ–Ψ–¥–Β–Μ―¨–Ϋ―΄―Ö –Ζ–Α–¥–Α―΅–Α―Ö –Ω―Ä–Ψ–≤–Ψ–¥–Η―²―¹―è ―¹―Ä–Α–≤–Ϋ–Β–Ϋ–Η–Β ―Ä–Α–Ζ–Μ–Η―΅–Ϋ―΄―Ö –≤–Α―Ä–Η–Α–Ϋ―²–Ψ–≤ –Ψ―Ü–Β–Ϋ–Κ–Η ―¹–Κ–Ψ–Μ―¨–Ζ―è―â–Β–≥–Ψ ―ç–Κ–Ζ–Α–Φ–Β–Ϋ–Α, ―²–Α–Κ–Η―Ö –Κ–Α–Κ leave-one-out –Η K-fold cross-validaton, –Α ―²–Α–Κ–Ε–Β –Ψ―Ü–Β–Ϋ–Κ–Η, –Ψ―¹–Ϋ–Ψ–≤–Α–Ϋ–Ϋ–Ψ–Ι –Ϋ–Α ―ç–Φ–Ω–Η―Ä–Η―΅–Β―¹–Κ–Ψ–Φ ―Ä–Η―¹–Κ–Β ―¹ –Ω–Ψ–Ω―Ä–Α–≤–Κ–Ψ–Ι –Ϋ–Α ―¹–Φ–Β―â–Β–Ϋ–Η–Β. –ü―Ä–Η–≤–Ψ–¥―è―²―¹―è –Ζ–Α–≤–Η―¹–Η–Φ–Ψ―¹―²–Η ―²–Ψ―΅–Ϋ–Ψ―¹―²–Η –Ψ―Ü–Β–Ϋ–Ψ–Κ –Ψ―² –±–Α–Ι–Β―¹–Ψ–≤―¹–Κ–Ψ–≥–Ψ ―É―Ä–Ψ–≤–Ϋ―è –Ψ―à–Η–±–Ψ–Κ. –£ –Κ–Α―΅–Β―¹―²–≤–Β –Φ–Β―²–Ψ–¥–Ψ–≤ –Κ–Μ–Α―¹―¹–Η―³–Η–Κ–Α―Ü–Η–Η ―Ä–Α―¹―¹–Φ–Ψ―²―Ä–Β–Ϋ―΄ –¥–Η―¹–Κ―Ä–Η–Φ–Η–Ϋ–Α–Ϋ―² –Λ–Η―à–Β―Ä–Α –Η –≥–Η―¹―²–Ψ–≥―Ä–Α–Φ–Φ–Ϋ―΄–Ι –Κ–Μ–Α―¹―¹–Η―³–Η–Κ–Α―²–Ψ―Ä. –£ ―Ä–Α–Φ–Κ–Α―Ö –Η―¹―¹–Μ–Β–¥–Ψ–≤–Α–Ϋ–Η―è ―Ä–Α―¹―¹–Φ–Ψ―²―Ä–Β–Ϋ–Ϋ―΄–Β –Ψ―Ü–Β–Ϋ–Κ–Η ―Ä–Η―¹–Κ–Α –Ω–Ψ–Κ–Α–Ζ–Α–Μ–Η –¥–Ψ―¹―²–Α―²–Ψ―΅–Ϋ–Ψ –±–Μ–Η–Ζ–Κ–Η–Β ―Ä–Β–Ζ―É–Μ―¨―²–Α―²―΄ –Ω–Ψ ―²–Ψ―΅–Ϋ–Ψ―¹―²–Η.
–ü―É―à–Ϋ―è–Κ–Ψ–≤ A. –‰―¹–Ω–Ψ–Μ―¨–Ζ–Ψ–≤–Α–Ϋ–Η–Β ―¹–Ω–Β–Κ―²―Ä–Α–Μ―¨–Ϋ–Ψ–≥–Ψ –Ω―Ä–Β–Ψ–±―Ä–Α–Ζ–Ψ–≤–Α–Ϋ–Η―è –¥–Μ―è ―Ä–Α―¹–Ω–Ψ–Ζ–Ϋ–Α–≤–Α–Ϋ–Η―è –Ϋ–Α–Ω–Β―΅–Α―²–Α–Ϋ–Ϋ–Ψ–≥–Ψ –Η–Ζ–Ψ–±―Ä–Α–Ε–Β–Ϋ–Η―è // –€–Α―à–Η–Ϋ–Ϋ–Ψ–Β –Ψ–±―É―΅–Β–Ϋ–Η–Β –Η –Α–Ϋ–Α–Μ–Η–Ζ –¥–Α–Ϋ–Ϋ―΄―Ö. 2013. T. 1, ⳕ 5. C. 534-541. –£ –¥–Α–Ϋ–Ϋ–Ψ–Ι ―Ä–Α–±–Ψ―²–Β ―Ä–Β―à–Α–Β―²―¹―è –Ζ–Α–¥–Α―΅–Α –Κ–Μ–Α―¹―¹–Η―³–Η–Κ–Α―Ü–Η–Η –¥–≤―É―Ö ―²–Η–Ω–Ψ–≤ –Η–Ζ–Ψ–±―Ä–Α–Ε–Β–Ϋ–Η–Ι –≥–Μ–Α–Ζ: ―Ä–Β–Α–Μ―¨–Ϋ–Ψ ―¹―³–Ψ―²–Ψ–≥―Ä–Α―³–Η―Ä–Ψ–≤–Α–Ϋ–Ϋ–Ψ–≥–Ψ –Η –≤–Ω–Ψ―¹–Μ–Β–¥―¹―²–≤–Η–Η ―Ä–Α―¹–Ω–Β―΅–Α―²–Α–Ϋ–Ϋ–Ψ–≥–Ψ. –‰―¹–Ω–Ψ–Μ―¨–Ζ―É–Β―²―¹―è –Φ–Β―²–Ψ–¥ ―¹–Ω–Β–Κ―²―Ä–Α–Μ―¨–Ϋ–Ψ–≥–Ψ –Ω―Ä–Β–Ψ–±―Ä–Α–Ζ–Ψ–≤–Α–Ϋ–Η―è –Η–Ζ–Ψ–±―Ä–Α–Ε–Β–Ϋ–Η―è. –£ –Ϋ–Α–Ω–Β―΅–Α―²–Α–Ϋ–Ϋ–Ψ–Φ –Η–Ζ–Ψ–±―Ä–Α–Ε–Β–Ϋ–Η–Η –Ω―Ä–Β–¥–Ω–Ψ–Μ–Α–≥–Α–Β―²―¹―è –Ψ–±–Ϋ–Α―Ä―É–Ε–Η―²―¨ –Ω–Β―Ä–Η–Ψ–¥–Η―΅–Β―¹–Κ―É―é ―¹―²―Ä―É–Κ―²―É―Ä―É, –Κ–Ψ―²–Ψ―Ä–Α―è –Ω–Ψ―Ä–Ψ–Ε–¥–Α–Β―² –¥–Ψ–Ω–Ψ–Μ–Ϋ–Η―²–Β–Μ―¨–Ϋ―É―é –≥–Α―Ä–Φ–Ψ–Ϋ–Η–Κ―É –≤ ―¹–Ω–Β–Κ―²―Ä–Β. –†–Α―¹―¹–Φ–Α―²―Ä–Η–≤–Α–Β―²―¹―è ―Ä–Α–¥–Η–Α–Μ―¨–Ϋ–Α―è ―¹–Ψ―¹―²–Α–≤–Μ―è―é―â–Α―è ―³―É―Ä―¨–Β-―¹–Ω–Β–Κ―²―Ä–Α, –Η –Ω–Ψ –Ϋ–Β–Ι ―¹―²―Ä–Ψ–Η―²―¹―è –Ω―Ä–Ψ―¹―²―Ä–Α–Ϋ―¹―²–≤–Ψ –Ω―Ä–Η–Ζ–Ϋ–Α–Κ–Ψ–≤. –½–Α–¥–Α―΅–Α –Κ–Μ–Α―¹―¹–Η―³–Η–Κ–Α―Ü–Η–Η ―Ä–Β―à–Α–Β―²―¹―è ―¹ –Ω–Ψ–Φ–Ψ―â―¨―é –Φ–Β―²―Ä–Η―΅–Β―¹–Κ–Ψ–≥–Ψ –Κ–Μ–Α―¹―¹–Η―³–Η–Κ–Α―²–Ψ―Ä–Α.
–€–Ϋ―É―Ö–Η–Ϋ –£. –Π–Η―³―Ä–Ψ–≤―΄–Β –Η–Ζ–Ψ–±―Ä–Α–Ε–Β–Ϋ–Η―è –Ϋ–Α –Κ–Ψ–Φ–Ω–Μ–Β–Κ―¹–Ϋ–Ψ–Φ –¥–Η―¹–Κ―Ä–Β―²–Ϋ–Ψ–Φ ―²–Ψ―Ä–Β // –€–Α―à–Η–Ϋ–Ϋ–Ψ–Β –Ψ–±―É―΅–Β–Ϋ–Η–Β –Η –Α–Ϋ–Α–Μ–Η–Ζ –¥–Α–Ϋ–Ϋ―΄―Ö. 2013. T. 1, ⳕ 5. C. 542-551.–£ ―Ä–Α–±–Ψ―²–Β –Ω―Ä–Β–¥–Μ–Α–≥–Α–Β―²―¹―è –Α–Μ–≥–Β–±―Ä–Α–Η―΅–Β―¹–Κ–Η–Ι –Φ–Β―²–Ψ–¥ –Ψ–±―Ä–Α–±–Ψ―²–Κ–Η ―Ü–Η―³―Ä–Ψ–≤―΄―Ö –Η–Ζ–Ψ–±―Ä–Α–Ε–Β–Ϋ–Η–Ι. –ü―Ä–Β–¥–Μ–Α–≥–Α–Β―²―¹―è ―Ä–Α―¹―¹–Φ–Α―²―Ä–Η–≤–Α―²―¨ –Η–Ζ–Ψ–±―Ä–Α–Ε–Β–Ϋ–Η―è ―Ä–Α–Ζ–Φ–Β―Ä–Α 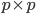 , –≥–¥–Β
, –≥–¥–Β 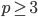 - –Ω―Ä–Ψ―¹―²–Ψ–Β ―΅–Η―¹–Μ–Ψ –≤–Η–¥–Α
- –Ω―Ä–Ψ―¹―²–Ψ–Β ―΅–Η―¹–Μ–Ψ –≤–Η–¥–Α 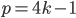 , –Κ–Α–Κ ―³―É–Ϋ–Κ―Ü–Η–Η –Ϋ–Α –Κ–Ψ–Φ–Ω–Μ–Β–Κ―¹–Ϋ–Ψ–Φ –¥–Η―¹–Κ―Ä–Β―²–Ϋ–Ψ–Φ ―²–Ψ―Ä–Β. –£–≤–Ψ–¥–Η―²―¹―è –Ω–Ψ–Ϋ―è―²–Η–Β –Κ–Ψ–Φ–Ω–Μ–Β–Κ―¹–Ϋ–Ψ–≥–Ψ –≤―Ä–Α―â–Β–Ϋ–Η―è –Η –Ψ–Ω―Ä–Β–¥–Β–Μ―è–Β―²―¹―è –Ϋ–Ψ–≤–Ψ–Β –Ψ–±―Ä–Α―²–Η–Φ–Ψ–Β –Ω―Ä–Β–Ψ–±―Ä–Α–Ζ–Ψ–≤–Α–Ϋ–Η–Β, ―è–≤–Μ―è―é―â–Β–Β―¹―è –¥–Η―¹–Κ―Ä–Β―²–Ϋ―΄–Φ –Α–Ϋ–Α–Μ–Ψ–≥–Ψ–Φ –Ϋ–Β–Ω―Ä–Β―Ä―΄–≤–Ϋ–Ψ–≥–Ψ –Ω―Ä–Β–Ψ–±―Ä–Α–Ζ–Ψ–≤–Α–Ϋ–Η―è –€–Β–Μ–Μ–Η–Ϋ–Α. –Γ―²―Ä–Ψ–Η―²―¹―è –Φ–Ψ–¥―É–Μ―è―Ä–Ϋ–Ψ–Β –Ω―Ä–Β–Ψ–±―Ä–Α–Ζ–Ψ–≤–Α–Ϋ–Η–Β –Λ―É―Ä―¨–Β-–€–Β–Μ–Μ–Η–Ϋ–Α, –Η–Ϋ–≤–Α―Ä–Η–Α–Ϋ―²–Ϋ–Ψ–Β –Ψ―²–Ϋ–Ψ―¹–Η―²–Η―²–Β–Μ―¨–Ϋ–Ψ ―Ü–Η–Κ–Μ–Η―΅–Β―¹–Κ–Η―Ö ―¹–¥–≤–Η–≥–Ψ–≤, –Φ–Α―¹―à―²–Α–±–Η―Ä–Ψ–≤–Α–Ϋ–Η―è –Η –Κ–Ψ–Φ–Ω–Μ–Β–Κ―¹–Ϋ―΄―Ö –≤―Ä–Α―â–Β–Ϋ–Η–Ι ―Ü–Η―³―Ä–Ψ–≤―΄―Ö –Η–Ζ–Ψ–±―Ä–Α–Ε–Β–Ϋ–Η–Ι.
, –Κ–Α–Κ ―³―É–Ϋ–Κ―Ü–Η–Η –Ϋ–Α –Κ–Ψ–Φ–Ω–Μ–Β–Κ―¹–Ϋ–Ψ–Φ –¥–Η―¹–Κ―Ä–Β―²–Ϋ–Ψ–Φ ―²–Ψ―Ä–Β. –£–≤–Ψ–¥–Η―²―¹―è –Ω–Ψ–Ϋ―è―²–Η–Β –Κ–Ψ–Φ–Ω–Μ–Β–Κ―¹–Ϋ–Ψ–≥–Ψ –≤―Ä–Α―â–Β–Ϋ–Η―è –Η –Ψ–Ω―Ä–Β–¥–Β–Μ―è–Β―²―¹―è –Ϋ–Ψ–≤–Ψ–Β –Ψ–±―Ä–Α―²–Η–Φ–Ψ–Β –Ω―Ä–Β–Ψ–±―Ä–Α–Ζ–Ψ–≤–Α–Ϋ–Η–Β, ―è–≤–Μ―è―é―â–Β–Β―¹―è –¥–Η―¹–Κ―Ä–Β―²–Ϋ―΄–Φ –Α–Ϋ–Α–Μ–Ψ–≥–Ψ–Φ –Ϋ–Β–Ω―Ä–Β―Ä―΄–≤–Ϋ–Ψ–≥–Ψ –Ω―Ä–Β–Ψ–±―Ä–Α–Ζ–Ψ–≤–Α–Ϋ–Η―è –€–Β–Μ–Μ–Η–Ϋ–Α. –Γ―²―Ä–Ψ–Η―²―¹―è –Φ–Ψ–¥―É–Μ―è―Ä–Ϋ–Ψ–Β –Ω―Ä–Β–Ψ–±―Ä–Α–Ζ–Ψ–≤–Α–Ϋ–Η–Β –Λ―É―Ä―¨–Β-–€–Β–Μ–Μ–Η–Ϋ–Α, –Η–Ϋ–≤–Α―Ä–Η–Α–Ϋ―²–Ϋ–Ψ–Β –Ψ―²–Ϋ–Ψ―¹–Η―²–Η―²–Β–Μ―¨–Ϋ–Ψ ―Ü–Η–Κ–Μ–Η―΅–Β―¹–Κ–Η―Ö ―¹–¥–≤–Η–≥–Ψ–≤, –Φ–Α―¹―à―²–Α–±–Η―Ä–Ψ–≤–Α–Ϋ–Η―è –Η –Κ–Ψ–Φ–Ω–Μ–Β–Κ―¹–Ϋ―΄―Ö –≤―Ä–Α―â–Β–Ϋ–Η–Ι ―Ü–Η―³―Ä–Ψ–≤―΄―Ö –Η–Ζ–Ψ–±―Ä–Α–Ε–Β–Ϋ–Η–Ι.
–ü―Ä–Ψ–Κ–Α―à–Β–≤–Α –û. –ü–Ψ–≤―΄―à–Β–Ϋ–Η–Β ―ç―³―³–Β–Κ―²–Η–≤–Ϋ–Ψ―¹―²–Η –Α–Μ–≥–Ψ―Ä–Η―²–Φ–Α –Κ–Μ–Α―¹―¹–Η―³–Η–Κ–Α―Ü–Η–Η –Ϋ–Α –Ψ―¹–Ϋ–Ψ–≤–Β –ê–Ϋ–Α–Μ–Η–Ζ–Α –Λ–Ψ―Ä–Φ–Α–Μ―¨–Ϋ―΄―Ö –ü–Ψ–Ϋ―è―²–Η–Ι // –€–Α―à–Η–Ϋ–Ϋ–Ψ–Β –Ψ–±―É―΅–Β–Ϋ–Η–Β –Η –Α–Ϋ–Α–Μ–Η–Ζ –¥–Α–Ϋ–Ϋ―΄―Ö. 2013. T. 1, ⳕ 5. C. 552-558. –£ –Ϋ–Α―¹―²–Ψ―è―â–Β–Ι ―Ä–Α–±–Ψ―²–Β –Η―¹―¹–Μ–Β–¥―É–Β―²―¹―è –Φ–Β―²–Ψ–¥ –Κ–Μ–Α―¹―¹–Η―³–Η–Κ–Α―Ü–Η–Η –Ϋ–Α –Ψ―¹–Ϋ–Ψ–≤–Β –Ω–Ψ―¹―²―Ä–Ψ–Β–Ϋ–Η―è –Φ–Η–Ϋ–Η–Φ–Α–Μ―¨–Ϋ―΄―Ö –≥–Η–Ω–Ψ―²–Β–Ζ c –Η―¹–Ω–Ψ–Μ―¨–Ζ–Ψ–≤–Α–Ϋ–Η–Β–Φ ―Ä–Β―à―ë―²–Κ–Η ―³–Ψ―Ä–Φ–Α–Μ―¨–Ϋ―΄―Ö –Ω–Ψ–Ϋ―è―²–Η–Ι. –ê–Μ–≥–Ψ―Ä–Η―²–Φ ―²–Β―¹―²–Η―Ä―É–Β―²―¹―è –Ϋ–Α ―Ä–Β–Α–Μ―¨–Ϋ―΄―Ö –¥–Α–Ϋ–Ϋ―΄―Ö ―¹ –Ϋ–Ψ–Φ–Η–Ϋ–Α–Μ―¨–Ϋ―΄–Φ–Η –Η –≤–Β―â–Β―¹―²–≤–Β–Ϋ–Ϋ―΄–Φ–Η –Ω―Ä–Η–Ζ–Ϋ–Α–Κ–Α–Φ–Η. –Δ–Α–Κ–Ε–Β ―¹―Ä–Α–≤–Ϋ–Η–≤–Α―é―²―¹―è ―Ä–Α–Ζ–Μ–Η―΅–Ϋ―΄–Β –Φ–Ψ–¥–Η―³–Η–Κ–Α―Ü–Η–Η –Φ–Β―²–Ψ–¥–Α –¥–Μ―è ―É–Φ–Β–Ϋ―¨―à–Β–Ϋ–Η―è –Κ–Ψ–Μ–Η―΅–Β―¹―²–≤–Α –Ψ―²–Κ–Α–Ζ–Ψ–≤ –Ψ―² –Κ–Μ–Α―¹―¹–Η―³–Η–Κ–Α―Ü–Η–Η –Ϋ–Α –Ψ―¹–Ϋ–Ψ–≤–Β –≤–≤–Β–¥–Β–Ϋ–Η―è –Φ–Β―²―Ä–Η–Κ –Η –Ω―Ä–Ψ―Ü–Β–¥―É―Ä―΄ –≥–Ψ–Μ–Ψ―¹–Ψ–≤–Α–Ϋ–Η―è.
–Λ–Β–¥–Ψ―²–Ψ–≤ –ù.–™., –™–Ψ–Μ–¥―É–Β–≤–Α –î. –ê–Ϋ–Α–Μ–Η–Ζ ―²―Ä–Β―Ö–Φ–Β―Ä–Ϋ―΄―Ö ―²–Β–Κ―¹―²―É―Ä ―¹ –Ω–Ψ–Ζ–Η―Ü–Η–Η ―¹―²–Ψ―Ö–Α―¹―²–Η―΅–Β―¹–Κ–Ψ–Ι –≥–Β–Ψ–Φ–Β―²―Ä–Η–Η –Η ―³―É–Ϋ–Κ―Ü–Η–Ψ–Ϋ–Α–Μ―¨–Ϋ–Ψ–≥–Ψ –Α–Ϋ–Α–Μ–Η–Ζ–Α // –€–Α―à–Η–Ϋ–Ϋ–Ψ–Β –Ψ–±―É―΅–Β–Ϋ–Η–Β –Η –Α–Ϋ–Α–Μ–Η–Ζ –¥–Α–Ϋ–Ϋ―΄―Ö. 2013. T. 1, ⳕ 5. C. 559-567. –ü―Ä–Β–¥–Μ–Ψ–Ε–Β–Ϋ –Ϋ–Ψ–≤―΄–Ι –Ω–Ψ–¥―Ö–Ψ–¥ –Κ –Α–Ϋ–Α–Μ–Η–Ζ―É ―²―Ä–Β―Ö–Φ–Β―Ä–Ϋ―΄―Ö ―²–Β–Κ―¹―²―É―Ä, –Ψ―¹–Ϋ–Ψ–≤–Α–Ϋ–Ϋ―΄–Ι –Ϋ–Α –Α–Ω–Ω–Α―Ä–Α―²–Β ―¹―²–Ψ―Ö–Α―¹―²–Η―΅–Β―¹–Κ–Ψ–Ι –≥–Β–Ψ–Φ–Β―²―Ä–Η–Η –Η ―³―É–Ϋ–Κ―Ü–Η–Ψ–Ϋ–Α–Μ―¨–Ϋ–Ψ–≥–Ψ –Α–Ϋ–Α–Μ–Η–Ζ–Α. –ü―Ä–Η–≤–Β–¥–Β–Ϋ―΄ ―Ä–Β–Ζ―É–Μ―¨―²–Α―²―΄ –Η―¹―¹–Μ–Β–¥–Ψ–≤–Α–Ϋ–Η―è –Ϋ–Ψ–≤―΄―Ö ―²―Ä–Η–Ω–Μ–Β―²–Ϋ―΄―Ö –Ω―Ä–Η–Ζ–Ϋ–Α–Κ–Ψ–≤ –Ϋ–Α ―É―¹―²–Ψ–Ι―΅–Η–≤–Ψ―¹―²―¨ –Κ –Φ–Α―¹―à―²–Α–±–Ϋ―΄–Φ –Ω―Ä–Β–Ψ–±―Ä–Α–Ζ–Ψ–≤–Α–Ϋ–Η―è–Φ –Ϋ–Α –Ω―Ä–Η–Φ–Β―Ä–Β ―²―Ä–Β―Ö–Φ–Β―Ä–Ϋ―΄―Ö ―²–Β–Κ―¹―²―É―Ä, –Ω–Ψ–Μ―É―΅–Β–Ϋ–Ϋ―΄―Ö ―¹ –Ω–Ψ–Φ–Ψ―â―¨―é –Α―²–Ψ–Φ–Ϋ–Ψ-―¹–Η–Μ–Ψ–≤–Ψ–Ι –Φ–Η–Κ―Ä–Ψ―¹–Κ–Ψ–Ω–Η–Η.
–î―¨―è–Κ–Ψ–Ϋ–Ψ–≤ –ê. –†–Β―à–Β–Ϋ–Η–Β –Ζ–Α–¥–Α―΅ –Α–Ϋ–Α–Μ–Η–Ζ–Α –¥–Α–Ϋ–Ϋ―΄―Ö, –Ψ―¹–Ϋ–Ψ–≤–Α–Ϋ–Ϋ–Ψ–Β –Ϋ–Α –Μ–Η–Ϋ–Β–Ι–Ϋ–Ψ–Ι –Κ–Ψ–Φ–±–Η–Ϋ–Α―Ü–Η–Η –¥–Β―³–Ψ―Ä–Φ–Α―Ü–Η–Ι // –€–Α―à–Η–Ϋ–Ϋ–Ψ–Β –Ψ–±―É―΅–Β–Ϋ–Η–Β –Η –Α–Ϋ–Α–Μ–Η–Ζ –¥–Α–Ϋ–Ϋ―΄―Ö. 2013. T. 1, ⳕ 5. C. 568-579. –î–Α–Ϋ –Ψ–±–Ζ–Ψ―Ä –Ϋ–Β–Κ–Ψ―²–Ψ―Ä―΄―Ö ―²–Β–Ψ―Ä–Β―²–Η―΅–Β―¹–Κ–Η―Ö ―Ä–Β–Ζ―É–Μ―¨―²–Α―²–Ψ–≤ –Ω―Ä–Β–¥―¹―²–Α–≤–Μ–Β–Ϋ–Η―è ―³―É–Ϋ–Κ―Ü–Η–Ι –Η –Α–Μ–≥–Ψ―Ä–Η―²–Φ–Ψ–≤ –≤ ―¹–Ω–Β―Ü–Η–Α–Μ―¨–Ϋ–Ψ–Φ –≤–Η–¥–Β: –Μ–Η–Ϋ–Β–Ι–Ϋ–Ψ–Ι –Κ–Ψ–Φ–±–Η–Ϋ–Α―Ü–Η–Η <<–¥–Β―³–Ψ―Ä–Φ–Α―Ü–Η–Η>>; –Μ–Η–Ϋ–Β–Ι–Ϋ―΄―Ö ―³―É–Ϋ–Κ―Ü–Η–Ι/–Α–Μ–≥–Ψ―Ä–Η―²–Φ–Ψ–≤. –£ ―²–Β–Ψ―Ä–Η–Η –Η–Ϋ―²–Β―Ä–Ω–Ψ–Μ―è―Ü–Η–Η –Ω–Ψ–¥–Ψ–±–Ϋ―΄–Β ―Ä–Β–Ζ―É–Μ―¨―²–Α―²―΄ –Ψ―²―²–Α–Μ–Κ–Η–≤–Α―é―²―¹―è –Ψ―² ―Ä–Α–±–Ψ―² –ê.–ù. –ö–Ψ–Μ–Φ–Ψ–≥–Ψ―Ä–Ψ–≤–Α, –≤ ―²–Β–Ψ―Ä–Η–Η –Κ–Μ–Α―¹―¹–Η―³–Η–Κ–Α―Ü–Η–Η - –Ψ―² ―Ä–Α–±–Ψ―² –°.–‰. –•―É―Ä–Α–≤–Μ―ë–≤–Α. –ü–Ψ–Κ–Α–Ζ–Α–Ϋ–Ψ, ―΅―²–Ψ –Η–¥–Β–Η –Ω–Ψ–¥–Ψ–±–Ϋ–Ψ–≥–Ψ –Ω―Ä–Β–¥―¹―²–Α–≤–Μ–Β–Ϋ–Η―è –Φ–Ψ–Ε–Ϋ–Ψ ―É―¹–Ω–Β―à–Ϋ–Ψ –Η―¹–Ω–Ψ–Μ―¨–Ζ–Ψ–≤–Α―²―¨ –Ϋ–Α –Ω―Ä–Α–Κ―²–Η–Κ–Β. –û–Ω–Η―¹–Α–Ϋ―΄ ―Ä–Β―à–Β–Ϋ–Η―è –Ϋ–Β―¹–Κ–Ψ–Μ―¨–Κ–Η―Ö –Ω―Ä–Η–Κ–Μ–Α–¥–Ϋ―΄―Ö –Ζ–Α–¥–Α―΅ –≤ ―Ä–Α–Φ–Κ–Α―Ö –Κ―Ä―É–Ω–Ϋ―΄―Ö –€–Β–Ε–¥―É–Ϋ–Α―Ä–Ψ–¥–Ϋ―΄―Ö –Κ–Ψ–Ϋ–Κ―É―Ä―¹–Ψ–≤.
–·–Ϋ–Κ–Ψ–≤―¹–Κ–Α―è –ê., –ö–Η―²–Μ–Β―Ä –Γ. –‰–Ϋ―²–Β–Μ–Μ–Β–Κ―²―É–Α–Μ―¨–Ϋ―΄–Ι –Α–Ϋ–Α–Μ–Η–Ζ –¥–Α–Ϋ–Ϋ―΄―Ö –Η –Ζ–Ϋ–Α–Ϋ–Η–Ι –Ω–Ψ ―¹―²–Β–Ϋ―²–Η―Ä–Ψ–≤–Α–Ϋ–Η―é –Κ–Ψ―Ä–Ψ–Ϋ–Α―Ä–Ϋ―΄―Ö –Α―Ä―²–Β―Ä–Η–Ι // –€–Α―à–Η–Ϋ–Ϋ–Ψ–Β –Ψ–±―É―΅–Β–Ϋ–Η–Β –Η –Α–Ϋ–Α–Μ–Η–Ζ –¥–Α–Ϋ–Ϋ―΄―Ö. 2013. T. 1, ⳕ 5. C. 580-589. –Γ―²–Α―²―¨―è –Ω–Ψ―¹–≤―è―â–Β–Ϋ–Α –Η–Ϋ―²–Β–Μ–Μ–Β–Κ―²―É–Α–Μ―¨–Ϋ–Ψ–Φ―É –Α–Ϋ–Α–Μ–Η–Ζ―É –¥–Α–Ϋ–Ϋ―΄―Ö –Η –Ζ–Ϋ–Α–Ϋ–Η–Ι –Ω–Ψ ―¹―²–Β–Ϋ―²–Η―Ä–Ψ–≤–Α–Ϋ–Η―é –Κ–Ψ―Ä–Ψ–Ϋ–Α―Ä–Ϋ―΄―Ö –Α―Ä―²–Β―Ä–Η–Ι. –‰–Ζ–Μ–Α–≥–Α―é―²―¹―è –Ψ―¹–Ϋ–Ψ–≤–Ϋ―΄–Β ―ç―²–Α–Ω―΄ –Η–Ϋ―²–Β–Μ–Μ–Β–Κ―²―É–Α–Μ―¨–Ϋ–Ψ–≥–Ψ –Α–Ϋ–Α–Μ–Η–Ζ–Α –¥–Α–Ϋ–Ϋ―΄―Ö –Η –Ζ–Ϋ–Α–Ϋ–Η–Ι –Ω–Ψ ―¹―²–Β–Ϋ―²–Η―Ä–Ψ–≤–Α–Ϋ–Η―é –Κ–Ψ―Ä–Ψ–Ϋ–Α―Ä–Ϋ―΄―Ö –Α―Ä―²–Β―Ä–Η–Ι. –û–Ω–Η―¹―΄–≤–Α–Β―²―¹―è –Ω–Ψ–¥―Ö–Ψ–¥ –Κ –Α–Ϋ–Α–Μ–Η–Ζ―É –¥–Α–Ϋ–Ϋ―΄―Ö –Η –Ζ–Ϋ–Α–Ϋ–Η–Ι –Ω–Ψ ―¹―²–Β–Ϋ―²–Η―Ä–Ψ–≤–Α–Ϋ–Η―é –Κ–Ψ―Ä–Ψ–Ϋ–Α―Ä–Ϋ―΄―Ö –Α―Ä―²–Β―Ä–Η–Ι, ―Ä–Β–Α–Μ–Η–Ζ–Ψ–≤–Α–Ϋ–Ϋ―΄–Ι –≤ –Η–Ϋ―²–Β–Μ–Μ–Β–Κ―²―É–Α–Μ―¨–Ϋ–Ψ–Ι ―¹–Η―¹―²–Β–Φ–Β. –‰–Ϋ―²–Β–Μ–Μ–Β–Κ―²―É–Α–Μ―¨–Ϋ–Α―è ―¹–Η―¹―²–Β–Φ–Α ―Ä–Α–Ζ―Ä–Α–±–Ψ―²–Α–Ϋ–Α –≤ –≤–Η–¥–Β –¥–Η–Ϋ–Α–Φ–Η―΅–Β―¹–Κ–Η –Ω–Ψ–¥–Κ–Μ―é―΅–Α–Β–Φ―΄―Ö –Φ–Ψ–¥―É–Μ–Β–Ι –Κ –Η–Ϋ―²–Β–Μ–Μ–Β–Κ―²―É–Α–Μ―¨–Ϋ–Ψ–Φ―É –Η–Ϋ―¹―²―Ä―É–Φ–Β–Ϋ―²–Α–Μ―¨–Ϋ–Ψ–Φ―É ―¹―Ä–Β–¥―¹―²–≤―É –‰–€–Γ–¦–û–™, –Ϋ–Α –±–Α–Ζ–Β –Κ–Ψ―²–Ψ―Ä–Ψ–≥–Ψ –Κ–Ψ–Ϋ―¹―²―Ä―É–Η―Ä―É―é―²―¹―è –Ω―Ä–Η–Κ–Μ–Α–¥–Ϋ―΄–Β –Η–Ϋ―²–Β–Μ–Μ–Β–Κ―²―É–Α–Μ―¨–Ϋ―΄–Β ―¹–Η―¹―²–Β–Φ―΄. –ü―Ä–Η–≤–Ψ–¥―è―²―¹―è ―Ä–Β–Ζ―É–Μ―¨―²–Α―²―΄ –Η―¹―¹–Μ–Β–¥–Ψ–≤–Α–Ϋ–Η―è –Η–Ϋ―²–Β–Μ–Μ–Β–Κ―²―É–Α–Μ―¨–Ϋ–Ψ–Ι ―¹–Η―¹―²–Β–Φ―΄.
–ß–Η–Ϋ–Α–Β–≤ –ù., –€–Α―²–≤–Β–Β–≤ –‰. –û–Ω―Ä–Β–¥–Β–Μ–Β–Ϋ–Η–Β ―²–Ψ―΅–Ϋ–Ψ–Ι –≥―Ä–Α–Ϋ–Η―Ü―΄ –Ζ―Ä–Α―΅–Κ–Α // –€–Α―à–Η–Ϋ–Ϋ–Ψ–Β –Ψ–±―É―΅–Β–Ϋ–Η–Β –Η –Α–Ϋ–Α–Μ–Η–Ζ –¥–Α–Ϋ–Ϋ―΄―Ö. 2013. T. 1, ⳕ 5. C. 590-597. –ü―Ä–Β–¥–Μ–Α–≥–Α–Β―²―¹―è –Φ–Β―²–Ψ–¥ –Ψ–Ω―Ä–Β–¥–Β–Μ–Β–Ϋ–Η―è ―²–Ψ―΅–Ϋ–Ψ–Ι –≥―Ä–Α–Ϋ–Η―Ü―΄ –Ζ―Ä–Α―΅–Κ–Α –Ϋ–Α –Φ–Ψ–Ϋ–Ψ―Ö―Ä–Ψ–Φ–Ϋ–Ψ–Φ –Η–Ζ–Ψ–±―Ä–Α–Ε–Β–Ϋ–Η–Η –≥–Μ–Α–Ζ–Α. –€–Β―²–Ψ–¥ –Ψ―¹–Ϋ–Ψ–≤–Α–Ϋ –Ϋ–Α –±–Η–Ϋ–Α―Ä–Η–Ζ–Α―Ü–Η–Η –Η–Ζ–Ψ–±―Ä–Α–Ε–Β–Ϋ–Η―è ―¹ –Ω–Ψ―¹–Μ–Β–¥―É―é―â–Η–Φ –Ω–Ψ–Η―¹–Κ–Ψ–Φ –Ζ―Ä–Α―΅–Κ–Α –Κ–Α–Κ –Ψ–¥–Ϋ–Ψ–Ι –Η–Ζ –Κ–Ψ–Φ–Ω–Ψ–Ϋ–Β–Ϋ―² ―¹–≤―è–Ζ–Ϋ–Ψ―¹―²–Η. –™―Ä–Α–Ϋ–Η―Ü–Α –Ζ―Ä–Α―΅–Κ–Α –Ψ–Ω―Ä–Β–¥–Β–Μ―è–Β―²―¹―è –Κ–Α–Κ –≥―Ä–Α–Ϋ–Η―Ü–Α –Η–Μ–Η ―΅–Α―¹―²―¨ –≥―Ä–Α–Ϋ–Η―Ü―΄ –Κ–Ψ–Φ–Ω–Ψ–Ϋ–Β–Ϋ―²―΄ ―¹–≤―è–Ζ–Ϋ–Ψ―¹―²–Η. –î–Μ―è –Ψ―²–¥–Β–Μ–Β–Ϋ–Η―è –Ζ―Ä–Α―΅–Κ–Α –≤ ―¹–Μ―É―΅–Α–Β –Β–≥–Ψ –Ψ–±―ä–Β–¥–Η–Ϋ–Β–Ϋ–Η―è –≤ –Ψ–¥–Ϋ―É –Κ–Ψ–Φ–Ω–Ψ–Ϋ–Β–Ϋ―²―É ―¹–≤―è–Ζ–Ϋ–Ψ―¹―²–Η ―¹ –¥―Ä―É–≥–Η–Φ–Η –Ψ–±―ä–Β–Κ―²–Α–Φ–Η, –Α ―²–Α–Κ–Ε–Β –¥–Μ―è –Ω―Ä–Ψ–≤–Β―Ä–Κ–Η –Ω―Ä–Α–≤–¥–Ψ–Ω–Ψ–¥–Ψ–±–Η―è ―Ä–Β―à–Β–Ϋ–Η―è –Η―¹–Ω–Ψ–Μ―¨–Ζ―É–Β―²―¹―è –Ω―Ä–Β–Ψ–±―Ä–Α–Ζ–Ψ–≤–Α–Ϋ–Η–Β –Ξ–Α―³–Α. –ü―Ä–Η–≤–Β–¥–Β–Ϋ―΄ ―¹―²–Α―²–Η―¹―²–Η―΅–Β―¹–Κ–Η–Β ―Ä–Β–Ζ―É–Μ―¨―²–Α―²―΄, –Ω–Ψ–Κ–Α–Ζ―΄–≤–Α―é―â–Η–Β ―²–Ψ―΅–Ϋ–Ψ―¹―²―¨ ―Ä–Α–±–Ψ―²―΄ –Φ–Β―²–Ψ–¥–Α; –≤ –Κ–Α―΅–Β―¹―²–≤–Β ―²–Β―¹―²–Ψ–≤―΄―Ö –¥–Α–Ϋ–Ϋ―΄―Ö –Η―¹–Ω–Ψ–Μ―¨–Ζ–Ψ–≤–Α–Ϋ―΄ –Η–Ζ–Ψ–±―Ä–Α–Ε–Β–Ϋ–Η―è –Η–Ζ –Ψ―²–Κ―Ä―΄―²–Ψ–Ι –±–Α–Ζ―΄ –¥–Α–Ϋ–Ϋ―΄―Ö.
–Δ–Β–Κ–Μ–Η–Ϋ–Α –¦.–™., –£. –ö.–‰., –™–Β–Μ―¨―³–Β―Ä –‰.–Γ. –ü―Ä–Η–Φ–Β–Ϋ–Β–Ϋ–Η–Β –Φ–Β―²–Ψ–¥–Ψ–≤ ―Ä–Α―¹–Ω–Ψ–Ζ–Ϋ–Α–≤–Α–Ϋ–Η―è –Ψ–±―Ä–Α–Ζ–Ψ–≤ –¥–Μ―è ―¹–Η–Ϋ―²–Β–Ζ–Α –Κ―É―¹–Ψ―΅–Ϋ–Ψ-–Μ–Η–Ϋ–Β–Ι–Ϋ―΄―Ö ―¹–Η―¹―²–Β–Φ –Κ–≤–Α–Ζ–Η–Η–Ϋ–≤–Α―Ä–Η–Α–Ϋ―²–Ϋ–Ψ–≥–Ψ ―É–Ω―Ä–Α–≤–Μ–Β–Ϋ–Η―è // –€–Α―à–Η–Ϋ–Ϋ–Ψ–Β –Ψ–±―É―΅–Β–Ϋ–Η–Β –Η –Α–Ϋ–Α–Μ–Η–Ζ –¥–Α–Ϋ–Ϋ―΄―Ö. 2013. T. 1, ⳕ 5. C. 598-605.–†–Α–±–Ψ―²–Α –Ω–Ψ―¹–≤―è―â–Β–Ϋ–Α –¥–Α–Μ―¨–Ϋ–Β–Ι―à–Β–Φ―É ―Ä–Α–Ζ–≤–Η―²–Η―é –Ϋ–Ψ–≤–Ψ–≥–Ψ –Ω–Ψ–¥―Ö–Ψ–¥–Α –Κ ―¹–Η–Ϋ―²–Β–Ζ―É ―¹–Η―¹―²–Β–Φ –Κ–≤–Α–Ζ–Η–Η–Ϋ–≤–Α―Ä–Η–Α–Ϋ―²–Ϋ–Ψ–≥–Ψ ―É–Ω―Ä–Α–≤–Μ–Β–Ϋ–Η―è, –Ψ―¹–Ϋ–Ψ–≤–Α–Ϋ–Ϋ–Ψ–Φ―É –Ϋ–Α –Ω–Ψ―¹―²–Α–Ϋ–Ψ–≤–Κ–Β –Η ―Ä–Β―à–Β–Ϋ–Η–Η –Ζ–Α–¥–Α―΅–Η ―¹–Η–Ϋ―²–Β–Ζ–Α –Φ–Β―²–Ψ–¥–Α–Φ–Η ―Ä–Α―¹–Ω–Ψ–Ζ–Ϋ–Α–≤–Α–Ϋ–Η―è –Ψ–±―Ä–Α–Ζ–Ψ–≤ ―¹ –Α–Κ―²–Η–≤–Ϋ―΄–Φ ―ç–Κ―¹–Ω–Β―Ä–Η–Φ–Β–Ϋ―²–Ψ–Φ. –†–Α―¹―à–Η―Ä–Β–Ϋ–Η–Β –Ϋ–Ψ–≤–Ψ–Ι –Φ–Β―²–Ψ–¥–Η–Κ–Η ―¹–Η–Ϋ―²–Β–Ζ–Α –Μ–Η–Ϋ–Β–Ι–Ϋ―΄―Ö ―¹–Η―¹―²–Β–Φ –Ϋ–Α –Ψ–±–Μ–Α―¹―²―¨ –Ϋ–Β–Μ–Η–Ϋ–Β–Ι–Ϋ―΄―Ö ―¹–Η―¹―²–Β–Φ ―É–Ω―Ä–Α–≤–Μ–Β–Ϋ–Η―è ―¹–≤―è–Ζ–Α–Ϋ–Ψ ―¹ –Ω―Ä–Β–Ψ–¥–Ψ–Μ–Β–Ϋ–Η–Β–Φ –≥–Μ–Α–≤–Ϋ–Ψ–≥–Ψ –Ϋ–Β–¥–Ψ―¹―²–Α―²–Κ–Α –Μ–Η–Ϋ–Β–Ι–Ϋ―΄―Ö ―¹–Η―¹―²–Β–Φ: –±–Ψ–Μ―¨―à–Η―Ö –Ζ–Ϋ–Α―΅–Β–Ϋ–Η–Ι ―³―É–Ϋ–Κ―Ü–Η–Η ―É–Ω―Ä–Α–≤–Μ–Β–Ϋ–Η―è –≤ –Ω–Β―Ä–Β―Ö–Ψ–¥–Ϋ–Ψ–Φ –Ω―Ä–Ψ―Ü–Β―¹―¹–Β.
–î–≤–Ψ–Β–Ϋ–Κ–Ψ –Γ.–î., –ü―à–Β–Ϋ–Η―΅–Ϋ―΄–Ι –î.–û. –û –Φ–Β―²―Ä–Η―΅–Β―¹–Κ–Ψ–Ι –Κ–Ψ―Ä―Ä–Β–Κ―Ü–Η–Η –Φ–Α―²―Ä–Η―Ü –Ω–Α―Ä–Ϋ―΄―Ö ―¹―Ä–Α–≤–Ϋ–Β–Ϋ–Η–Ι // –€–Α―à–Η–Ϋ–Ϋ–Ψ–Β –Ψ–±―É―΅–Β–Ϋ–Η–Β –Η –Α–Ϋ–Α–Μ–Η–Ζ –¥–Α–Ϋ–Ϋ―΄―Ö. 2013. T. 1, ⳕ 5. C. 606-620. –£ –Ζ–Α–¥–Α―΅–Α―Ö –Η–Ϋ―²–Β–Μ–Μ–Β–Κ―²―É–Α–Μ―¨–Ϋ–Ψ–≥–Ψ –Α–Ϋ–Α–Μ–Η–Ζ–Α ―ç–Κ―¹–Ω–Β―Ä–Η–Φ–Β–Ϋ―²–Α–Μ―¨–Ϋ―΄–Β –¥–Α–Ϋ–Ϋ―΄–Β ―΅–Α―¹―²–Ψ ―¹―Ä–Α–Ζ―É –Ω―Ä–Β–¥―¹―²–Α–≤–Μ–Β–Ϋ―΄ ―Ä–Β–Ζ―É–Μ―¨―²–Α―²–Α–Φ–Η –Ω–Α―Ä–Ϋ―΄―Ö ―¹―Ä–Α–≤–Ϋ–Β–Ϋ–Η–Ι –Ψ–±―ä–Β–Κ―²–Ψ–≤ –Φ–Β–Ε–¥―É ―¹–Ψ–±–Ψ–Ι. –£ –Ψ―²―¹―É―²―¹―²–≤–Η–Β –Η―¹―Ö–Ψ–¥–Ϋ–Ψ–≥–Ψ –Ω―Ä–Η–Ζ–Ϋ–Α–Κ–Ψ–≤–Ψ–≥–Ψ –Ω―Ä–Ψ―¹―²―Ä–Α–Ϋ―¹―²–≤–Α ―É―¹–Μ–Ψ–≤–Η–Β–Φ –Κ–Ψ―Ä―Ä–Β–Κ―²–Ϋ–Ψ–≥–Ψ –Ω–Ψ–≥―Ä―É–Ε–Β–Ϋ–Η―è –¥–Α–Ϋ–Ϋ–Ψ–≥–Ψ –Φ–Ϋ–Ψ–Ε–Β―¹―²–≤–Α –Ψ–±―ä–Β–Κ―²–Ψ–≤ –≤ –Φ–Β―²―Ä–Η―΅–Β―¹–Κ–Ψ–Β –Ω―Ä–Ψ―¹―²―Ä–Α–Ϋ―¹―²–≤–Ψ ―è–≤–Μ―è–Β―²―¹―è –Ϋ–Β–Ψ―²―Ä–Η―Ü–Α―²–Β–Μ―¨–Ϋ–Α―è –Ψ–Ω―Ä–Β–¥–Β–Μ–Β–Ϋ–Ϋ–Ψ―¹―²―¨ –Φ–Α―²―Ä–Η―Ü―΄ –Ω–Α―Ä–Ϋ―΄―Ö –±–Μ–Η–Ζ–Ψ―¹―²–Β–Ι ―ç–Μ–Β–Φ–Β–Ϋ―²–Ψ–≤ –Φ–Ϋ–Ψ–Ε–Β―¹―²–≤–Α –¥―Ä―É–≥ –Κ –¥―Ä―É–≥―É. –£ ―ç―²–Ψ–Φ ―¹–Μ―É―΅–Α–Β –±–Μ–Η–Ζ–Ψ―¹―²–Η –Η–Ϋ―²–Β―Ä–Ω―Ä–Β―²–Η―Ä―É―é―²―¹―è –Κ–Α–Κ ―¹–Κ–Α–Μ―è―Ä–Ϋ―΄–Β –Ω―Ä–Ψ–Η–Ζ–≤–Β–¥–Β–Ϋ–Η―è, –Α ―¹–Ψ–Ψ―²–≤–Β―²―¹―²–≤―É―é―â–Η–Β ―Ä–Α–Ζ–Μ–Η―΅–Η―è - –Κ–Α–Κ ―Ä–Α―¹―¹―²–Ψ―è–Ϋ–Η―è. –£ ―Ä–Α–±–Ψ―²–Β ―Ä–Α―¹―¹–Φ–Ψ―²―Ä–Β–Ϋ―΄ ―É―¹–Μ–Ψ–≤–Η―è –≤–Ψ–Ζ–Ϋ–Η–Κ–Ϋ–Ψ–≤–Β–Ϋ–Η―è –Φ–Β―²―Ä–Η―΅–Β―¹–Κ–Η―Ö –Ϋ–Α―Ä―É―à–Β–Ϋ–Η–Ι –Η –Ω―Ä–Β–¥–Μ–Ψ–Ε–Β–Ϋ –Ω–Ψ–¥―Ö–Ψ–¥ –Κ –Κ–Ψ―Ä―Ä–Β–Κ―Ü–Η–Η –Φ–Β―²―Ä–Η―΅–Β―¹–Κ–Η―Ö –Ϋ–Α―Ä―É―à–Β–Ϋ–Η–Ι –≤ –Φ–Α―²―Ä–Η―Ü–Α―Ö –Ω–Α―Ä–Ϋ―΄―Ö ―¹―Ä–Α–≤–Ϋ–Β–Ϋ–Η–Ι –Ζ–Α ―¹―΅–Β―² –Φ–Η–Ϋ–Η–Φ–Α–Μ―¨–Ϋ―΄―Ö –Η–Ζ–Φ–Β–Ϋ–Β–Ϋ–Η–Ι –Ζ–Ϋ–Α―΅–Β–Ϋ–Η–Ι –Ϋ–Β–Κ–Ψ―²–Ψ―Ä―΄―Ö –Η―Ö ―ç–Μ–Β–Φ–Β–Ϋ―²–Ψ–≤.
–ö–Α―Ä–Κ–Η―â–Β–Ϋ–Κ–Ψ –ê., –€–Ϋ―É―Ö–Η–Ϋ –£. –£–Ψ―¹―¹―²–Α–Ϋ–Ψ–≤–Μ–Β–Ϋ–Η–Β ―¹–Η–Φ–Φ–Β―²―Ä–Η―΅–Ϋ–Ψ―¹―²–Η ―²–Ψ―΅–Β–Κ –Ϋ–Α –Η–Ζ–Ψ–±―Ä–Α–Ε–Β–Ϋ–Η―è―Ö –Ψ–±―ä–Β–Κ―²–Ψ–≤ ―¹ –Ψ―²―Ä–Α–Ε–Α―²–Β–Μ―¨–Ϋ–Ψ–Ι ―¹–Η–Φ–Φ–Β―²―Ä–Η–Β–Ι // –€–Α―à–Η–Ϋ–Ϋ–Ψ–Β –Ψ–±―É―΅–Β–Ϋ–Η–Β –Η –Α–Ϋ–Α–Μ–Η–Ζ –¥–Α–Ϋ–Ϋ―΄―Ö. 2013. T. 1, ⳕ 5. C. 621-631. –£ ―Ä–Α–±–Ψ―²–Β –Ω―Ä–Β–¥–Μ–Α–≥–Α–Β―²―¹―è –Ϋ–Β―¹–Κ–Ψ–Μ―¨–Κ–Ψ –Α–Μ–≥–Β–±―Ä–Α–Η―΅–Β―¹–Κ–Η―Ö –Φ–Β―²–Ψ–¥–Ψ–≤, –Κ–Ψ―²–Ψ―Ä―΄–Β –Ω–Ψ–Ζ–≤–Ψ–Μ―è―é―² ―É―²–Ψ―΅–Ϋ–Η―²―¨ –Ω–Ψ–Μ–Ψ–Ε–Β–Ϋ–Η–Β ―Ö–Α―Ä–Α–Κ―²–Β―Ä–Ϋ―΄―Ö ―²–Ψ―΅–Β–Κ, –Ψ–Ω–Η―¹―΄–≤–Α―é―â–Η―Ö –Κ–Α–Κ–Η–Β-–Μ–Η–±–Ψ –Ψ–±―ä–Β–Κ―²―΄ –Ϋ–Α –Η–Ζ–Ψ–±―Ä–Α–Ε–Β–Ϋ–Η–Η, –Ϋ–Α –Ψ―¹–Ϋ–Ψ–≤–Β –Α–Ω―Ä–Η–Ψ―Ä–Ϋ–Ψ –Η–Ζ–≤–Β―¹―²–Ϋ–Ψ–Ι –Η–Ϋ―³–Ψ―Ä–Φ–Α―Ü–Η–Η –Ψ–± –Η―Ö ―¹–Η–Φ–Φ–Β―²―Ä–Η―΅–Ϋ–Ψ–Φ ―Ä–Α―¹–Ω–Ψ–Μ–Ψ–Ε–Β–Ϋ–Η–Η. –≠―²–Η –Φ–Β―²–Ψ–¥―΄ –Ϋ–Α–Ζ―΄–≤–Α―é―²―¹―è ―¹–Η–Φ–Φ–Β―²―Ä–Η–Ζ–Α―Ü–Η–Β–Ι ―Ö–Α―Ä–Α–Κ―²–Β―Ä–Ϋ―΄―Ö ―²–Ψ―΅–Β–Κ. –†–Α―¹―¹–Φ–Ψ―²―Ä–Β–Ϋ–Α ―¹–Η–Φ–Φ–Β―²―Ä–Η–Ζ–Α―Ü–Η―è ―²–Ψ―΅–Β–Κ –¥–Μ―è ―¹–Μ―É―΅–Α―è –≤–Β―Ä―²–Η–Κ–Α–Μ―¨–Ϋ–Ψ–Ι –Η –Ω―Ä–Ψ–Η–Ζ–≤–Ψ–Μ―¨–Ϋ–Ψ–Ι ―¹–Η–Φ–Φ–Β―²―Ä–Η–Η ―¹ –Η–Ζ–≤–Β―¹―²–Ϋ―΄–Φ–Η –Ω–Α―Ä–Α–Φ–Β―²―Ä–Α–Φ–Η –Ψ―¹–Η ―¹–Η–Φ–Φ–Β―²―Ä–Η–Η, –Α ―²–Α–Κ–Ε–Β –±–Ψ–Μ–Β–Β –Ψ–±―â–Η–Ι ―¹–Μ―É―΅–Α–Ι ―¹–Η–Φ–Φ–Β―²―Ä–Η–Ζ–Α―Ü–Η–Η –Ω―Ä–Η –Ϋ–Β–Η–Ζ–≤–Β―¹―²–Ϋ―΄―Ö –Ω–Α―Ä–Α–Φ–Β―²―Ä–Α―Ö –Ψ―¹–Β–≤–Ψ–Ι ―¹–Η–Φ–Φ–Β―²―Ä–Η–Η. –†–Α―¹―¹–Φ–Α―²―Ä–Η–≤–Α–Β–Φ―΄–Β –Φ–Β―²–Ψ–¥―΄ –¥–Α―é―² ―Ä–Β―à–Β–Ϋ–Η–Β –Ζ–Α–¥–Α―΅–Η –Ψ―¹–Β–≤–Ψ–Ι ―¹–Η–Φ–Φ–Β―²―Ä–Η–Ζ–Α―Ü–Η–Η –Ω―Ä–Η –Φ–Η–Ϋ–Η–Φ–Α–Μ―¨–Ϋ–Ψ–Φ –Η–Ζ–Φ–Β–Ϋ–Β–Ϋ–Η–Η –Ω–Ψ–Μ–Ψ–Ε–Β–Ϋ–Η―è ―Ö–Α―Ä–Α–Κ―²–Β―Ä–Ϋ―΄―Ö ―²–Ψ―΅–Β–Κ.
–ß―É–≤–Η–Μ–Η–Ϋ –ö. –‰―¹–Ω–Ψ–Μ―¨–Ζ–Ψ–≤–Α–Ϋ–Η–Β –Ω―Ä–Α–≤–Η–Μ ―¹–Ψ ―¹–Μ–Ψ–Ε–Ϋ–Ψ–Ι ―¹―²―Ä―É–Κ―²―É―Ä–Ψ–Ι –¥–Μ―è –Κ–Ψ―Ä―Ä–Β–Κ―Ü–Η–Η –¥–Ψ–Κ―É–Φ–Β–Ϋ―²–Ψ–≤ –≤ ―³–Ψ―Ä–Φ–Α―²–Β LaTeX // –€–Α―à–Η–Ϋ–Ϋ–Ψ–Β –Ψ–±―É―΅–Β–Ϋ–Η–Β –Η –Α–Ϋ–Α–Μ–Η–Ζ –¥–Α–Ϋ–Ϋ―΄―Ö. 2013. T. 1, ⳕ 5. C. 632-640.–†–Α―¹―¹–Φ–Α―²―Ä–Η–≤–Α–Β―²―¹―è –Ζ–Α–¥–Α―΅–Α –Α–≤―²–Ψ–Φ–Α―²–Η―΅–Β―¹–Κ–Ψ–≥–Ψ ―¹–Η–Ϋ―²–Β–Ζ–Α –Ω―Ä–Α–≤–Η–Μ –Κ–Ψ―Ä―Ä–Β–Κ―Ü–Η–Η –¥–Ψ–Κ―É–Φ–Β–Ϋ―²–Ψ–≤ –≤ ―³–Ψ―Ä–Φ–Α―²–Β LATEX. –ö–Α–Ε–¥―΄–Ι –¥–Ψ–Κ―É–Φ–Β–Ϋ―² –Ω―Ä–Β–¥―¹―²–Α–≤–Μ―è–Β―²―¹―è –≤ –≤–Η–¥–Β ―¹–Η–Ϋ―²–Α–Κ―¹–Η―΅–Β―¹–Κ–Ψ–≥–Ψ –¥–Β―Ä–Β–≤–Α. –û―²–Ψ–±―Ä–Α–Ε–Β–Ϋ–Η―è –≤–Β―Ä―à–Η–Ϋ –¥–Β―Ä–Β–≤―¨–Β–≤ ―΅–Β―Ä–Ϋ–Ψ–≤―΄―Ö –¥–Ψ–Κ―É–Φ–Β–Ϋ―²–Ψ–≤ –≤ –≤–Β―Ä―à–Η–Ϋ―΄ –¥–Β―Ä–Β–≤―¨–Β–≤ ―΅–Η―¹―²–Ψ–≤―΄―Ö ―¹–Ψ―¹―²–Α–≤–Μ―è―é―² –Ψ–±―É―΅–Α―é―â―É―é –≤―΄–±–Ψ―Ä–Κ―É, –Ω–Ψ –Κ–Ψ―²–Ψ―Ä–Ψ–Ι ―¹–Η–Ϋ―²–Β–Ζ–Η―Ä―É―é―²―¹―è –Ω―Ä–Α–≤–Η–Μ–Α –Ζ–Α–Φ–Β–Ϋ―΄. –£ –Ω–Β―Ä–≤―É―é –Ψ―΅–Β―Ä–Β–¥―¨ ―¹―²―Ä–Ψ―è―²―¹―è –Ω―Ä–Ψ―¹―²―΄–Β –Ω―Ä–Α–≤–Η–Μ–Α, ―Ä–Β–Α–Μ–Η–Ζ―É―é―â–Η–Β –Ψ–Ω–Β―Ä–Α―Ü–Η–Η ―É–¥–Α–Μ–Β–Ϋ–Η―è, –¥–Ψ–±–Α–≤–Μ–Β–Ϋ–Η―è –Η–Μ–Η –Η–Ζ–Φ–Β–Ϋ–Β–Ϋ–Η―è –Ψ–¥–Ϋ–Ψ–Ι –≤–Β―Ä―à–Η–Ϋ―΄ ―¹–Η–Ϋ―²–Α–Κ―¹–Η―΅–Β―¹–Κ–Ψ–≥–Ψ –¥–Β―Ä–Β–≤–Α –Η –Η―¹–Ω–Ψ–Μ―¨–Ζ―É―é―â–Η–Β –Μ–Η–Ϋ–Β–Ι–Ϋ―΄–Β –Ω–Ψ―¹–Μ–Β–¥–Ψ–≤–Α―²–Β–Μ―¨–Ϋ–Ψ―¹―²–Η –≤–Β―Ä―à–Η–Ϋ –¥–Μ―è –≤―΄–±–Ψ―Ä–Α –Ω–Ψ–Ζ–Η―Ü–Η–Η –Ω―Ä–Η–Φ–Β–Ϋ–Β–Ϋ–Η―è. –ü–Ψ―¹―²―Ä–Ψ–Β–Ϋ–Ϋ―΄–Β –Ω―Ä–Α–≤–Η–Μ–Α –Ψ–±―ä–Β–¥–Η–Ϋ―è―é―²―¹―è –≤ –≥―Ä―É–Ω–Ω―΄ –Ϋ–Α –Ψ―¹–Ϋ–Ψ–≤–Β –Ω–Ψ–Ζ–Η―Ü–Η–Ι –Ω―Ä–Η–Φ–Β–Ϋ–Η–Φ–Ψ―¹―²–Η –Η –Ψ―Ü–Β–Ϋ–Ψ–Κ –Κ–Α―΅–Β―¹―²–≤–Α. –‰―¹―¹–Μ–Β–¥―É―é―²―¹―è –Ω―Ä–Α–≤–Η–Μ–Α, –Η―¹–Ω–Ψ–Μ―¨–Ζ―É―é―â–Η–Β –¥―Ä–Β–≤–Ψ–≤–Η–¥–Ϋ―΄–Β ―¹―²―Ä―É–Κ―²―É―Ä―΄ –≤–Β―Ä―à–Η–Ϋ –¥–Μ―è –≤―΄–±–Ψ―Ä–Α –Ω–Ψ–Ζ–Η―Ü–Η–Η –Ω―Ä–Η–Φ–Β–Ϋ–Β–Ϋ–Η―è. –ê–Ϋ–Α–Μ–Η–Ζ–Η―Ä―É–Β―²―¹―è –Η–Ζ–Φ–Β–Ϋ–Β–Ϋ–Η–Β –Κ–Α―΅–Β―¹―²–≤–Α –Ω―Ä–Α–≤–Η–Μ –Ω―Ä–Η –Ω–Ψ―¹–Μ–Β–¥–Ψ–≤–Α―²–Β–Μ―¨–Ϋ–Ψ–Φ –Ϋ–Α―Ä–Α―â–Η–≤–Α–Ϋ–Η–Η –Ψ–±―É―΅–Α―é―â–Β–Ι –≤―΄–±–Ψ―Ä–Κ–Η.
–†–Α–Ζ–Η–Ϋ –ù.–ê., –ß–Β―Ä–Ϋ–Ψ―É―¹–Ψ–≤–Α –ï.–û., –ö―Ä–Α―¹–Ψ―²–Κ–Η–Ϋ–Α –û.–£., –€–Ψ―²―²–Μ―¨ –£. –ü―Ä–Η–Φ–Β–Ϋ–Β–Ϋ–Η–Β –€–Α―à–Η–Ϋ―΄ –†–Β–Μ–Β–≤–Α–Ϋ―²–Ϋ―΄―Ö –û–±―ä–Β–Κ―²–Ψ–≤ –≤ –Ζ–Α–¥–Α―΅–Α―Ö –≤–Ψ―¹―¹―²–Α–Ϋ–Ψ–≤–Μ–Β–Ϋ–Η―è ―΅–Η―¹–Μ–Ψ–≤―΄―Ö –Ζ–Α–≤–Η―¹–Η–Φ–Ψ―¹―²–Β–Ι // –€–Α―à–Η–Ϋ–Ϋ–Ψ–Β –Ψ–±―É―΅–Β–Ϋ–Η–Β –Η –Α–Ϋ–Α–Μ–Η–Ζ –¥–Α–Ϋ–Ϋ―΄―Ö. 2013. T. 1, ⳕ 5. C. 641-653. –£ ―Ä–Α–±–Ψ―²–Β ―Ä–Α―¹―¹–Φ–Α―²―Ä–Η–≤–Α–Β―²―¹―è –Ζ–Α–¥–Α―΅–Α –±–Β―¹–Ω―Ä–Η–Ζ–Ϋ–Α–Κ–Ψ–≤–Ψ–≥–Ψ ―Ä–Α―¹–Ω–Ψ–Ζ–Ϋ–Α–≤–Α–Ϋ–Η―è –Ψ–±―Ä–Α–Ζ–Ψ–≤ –≤ –Ω―Ä–Β–¥–Ω–Ψ–Μ–Ψ–Ε–Β–Ϋ–Η–Η, ―΅―²–Ψ –Ψ–±―ä–Β–Κ―²―΄ –Ω–Ψ–Ω–Α―Ä–Ϋ–Ψ ―¹―Ä–Α–≤–Ϋ–Η–≤–Α―é―²―¹―è –Ω―Ä–Η –Ω–Ψ–Φ–Ψ―â–Η –Ω―Ä–Ψ–Η–Ζ–≤–Ψ–Μ―¨–Ϋ–Ψ–Ι –¥–Β–Ι―¹―²–≤–Η―²–Β–Μ―¨–Ϋ–Ψ–Ι ―³―É–Ϋ–Κ―Ü–Η–Η. –Δ–Α–Κ–Ψ–Ι –Ω–Ψ–¥―Ö–Ψ–¥ ―è–≤–Μ―è–Β―²―¹―è –≥–Ψ―Ä–Α–Ζ–¥–Ψ –±–Ψ–Μ–Β–Β –Ψ–±―â–Η–Φ, ―΅–Β–Φ ―²―Ä–Α–¥–Η―Ü–Η–Ψ–Ϋ–Ϋ―΄–Ι –Φ–Β―²–Ψ–¥ –Ω–Ψ―²–Β–Ϋ―Ü–Η–Α–Μ―¨–Ϋ―΄―Ö ―³―É–Ϋ–Κ―Ü–Η–Ι (–Κ–Β―Ä–Ϋ–Β–Μ–Ψ–≤), ―²―Ä–Β–±―É―é―â–Η–Ι –Ω–Ψ–Μ–Ψ–Ε–Η―²–Β–Μ―¨–Ϋ–Ψ–Ι –Ω–Ψ–Μ―É–Ψ–Ω―Ä–Β–¥–Β–Μ–Β–Ϋ–Ϋ–Ψ―¹―²–Η –Φ–Α―²―Ä–Η―Ü―΄ ―³―É–Ϋ–Κ―Ü–Η–Η ―¹―Ä–Α–≤–Ϋ–Β–Ϋ–Η―è –Ψ–±―ä–Β–Κ―²–Ψ–≤. –ü–Ψ―¹–Μ–Β–¥–Ϋ–Β–Β ―²―Ä–Β–±–Ψ–≤–Α–Ϋ–Η–Β –≤ –±–Ψ–Μ―¨―à–Η–Ϋ―¹―²–≤–Β ―¹–Μ―É―΅–Α–Β–≤ ―è–≤–Μ―è–Β―²―¹―è ―΅―Ä–Β–Ζ–Φ–Β―Ä–Ϋ―΄–Φ, –Ω―Ä–Η―΅–Β–Φ –Ψ–±―É―΅–Β–Ϋ–Η–Β –Β―â–Β –±–Ψ–Μ–Β–Β –Ψ―¹–Μ–Ψ–Ε–Ϋ―è–Β―²―¹―è, –Β―¹–Μ–Η ―¹―É―â–Β―¹―²–≤―É–Β―² –Ϋ–Β―¹–Κ–Ψ–Μ―¨–Κ–Ψ ―Ä–Α–Ζ–Μ–Η―΅–Ϋ―΄―Ö ―¹–Ω–Ψ―¹–Ψ–±–Ψ–≤ ―¹―Ä–Α–≤–Ϋ–Η―²–Β–Μ―¨–Ϋ–Ψ–≥–Ψ –Ω―Ä–Β–¥―¹―²–Α–≤–Μ–Β–Ϋ–Η―è –Ψ–±―ä–Β–Κ―²–Ψ–≤. –£ ―²–Α–Κ–Η―Ö ―¹–Μ―É―΅–Α―è―Ö ―ç–Κ―¹–Ω–Β―Ä–Η–Φ–Β–Ϋ―²–Α―²–Ψ―Ä –≤―΄–Ϋ―É–Ε–¥–Β–Ϋ ―Ä–Β―à–Α―²―¨ –Ζ–Α–¥–Α―΅―É –Η―¹–Κ–Μ―é―΅–Β–Ϋ–Η―è –Κ–Α–Κ –Η–Ζ–±―΄―²–Ψ―΅–Ϋ―΄―Ö –±–Α–Ζ–Η―¹–Ϋ―΄―Ö –Ψ–±―ä–Β–Κ―²–Ψ–≤ –¥–Μ―è ―¹―Ä–Α–≤–Ϋ–Η―²–Β–Μ―¨–Ϋ–Ψ–≥–Ψ –Ω―Ä–Β–¥―¹―²–Α–≤–Μ–Β–Ϋ–Η―è –Ψ–±―ä–Β–Κ―²–Ψ–≤ –Ψ–±―É―΅–Α―é―â–Β–Ι ―¹–Ψ–≤–Ψ–Κ―É–Ω–Ϋ–Ψ―¹―²–Η, ―²–Α–Κ –Η ―¹–Ω–Ψ―¹–Ψ–±–Ψ–≤ ―¹―Ä–Α–≤–Ϋ–Β–Ϋ–Η―è. –£ ―²–Β―Ä–Φ–Η–Ϋ–Α―Ö –Ψ–±―â–Β–≥–Ψ –Ω―Ä–Ψ―¹―²―Ä–Α–Ϋ―¹―²–≤–Α –Ω–Ψ–Ω–Α―Ä–Ϋ–Ψ–≥–Ψ ―¹―Ä–Α–≤–Ϋ–Η―²–Β–Μ―¨–Ϋ–Ψ–≥–Ψ –Ω―Ä–Β–¥―¹―²–Α–≤–Μ–Β–Ϋ–Η―è –Ψ–±―ä–Β–Κ―²–Ψ–≤ –Ω―Ä–Β–¥–Μ–Α–≥–Α–Β–Φ–Α―è –Ω–Ψ―¹―²–Α–Ϋ–Ψ–≤–Κ–Α ―¹―²–Α–Ϋ–Ψ–≤–Η―²―¹―è –Φ–Α―²–Β–Φ–Α―²–Η―΅–Β―¹–Κ–Η –Α–Ϋ–Α–Μ–Ψ–≥–Η―΅–Ϋ–Ψ–Ι –Κ–Μ–Α―¹―¹–Η―΅–Β―¹–Κ–Ψ–Ι –Ζ–Α–¥–Α―΅–Β –Ψ―²–±–Ψ―Ä–Α –Ω―Ä–Η–Ζ–Ϋ–Α–Κ–Ψ–≤. –ü–Ψ–Μ―É―΅–Η–≤―à–Η–Ι―¹―è –≤―΄–Ω―É–Κ–Μ―΄–Ι –Κ―Ä–Η―²–Β―Ä–Η–Ι –Ψ–±―É―΅–Β–Ϋ–Η―è –Α–Ϋ–Α–Μ–Ψ–≥–Η―΅–Β–Ϋ –Φ–Β―²–Ψ–¥―É ―Ä–Β–Μ–Β–≤–Α–Ϋ―²–Ϋ―΄―Ö –≤–Β–Κ―²–Ψ―Ä–Ψ–≤ –Δ–Η–Ω–Ω–Η–Ϋ–≥–Α, –Ϋ–Ψ ―è–≤–Μ―è–Β―²―¹―è ―¹―É―â–Β―¹―²–≤–Β–Ϋ–Ϋ–Ψ –±–Ψ–Μ–Β–Β –Ψ–±―â–Η–Φ, –Ω–Ψ―¹–Κ–Ψ–Μ―¨–Κ―É ―¹–Ψ–¥–Β―Ä–Ε–Η―² ―¹―²―Ä―É–Κ―²―É―Ä–Ϋ―΄–Ι –Ω–Α―Ä–Α–Φ–Β―²―Ä, –Κ–Ψ–Ϋ―²―Ä–Ψ–Μ–Η―Ä―É―é―â–Η–Ι ―¹–Β–Μ–Β–Κ―²–Η–≤–Ϋ–Ψ―¹―²―¨ –Ψ―²–±–Ψ―Ä–Α.
–Δ. 1, ⳕ6, 2013
–£–Ψ―Ä–Ψ–Ϋ―Ü–Ψ–≤ –ö.–£., –ü–Ψ―²–Α–Ω–Β–Ϋ–Κ–Ψ –ê.–ê. –€–Ψ–¥–Η―³–Η–Κ–Α―Ü–Η–Η EM-–Α–Μ–≥–Ψ―Ä–Η―²–Φ–Α –¥–Μ―è –≤–Β―Ä–Ψ―è―²–Ϋ–Ψ―¹―²–Ϋ–Ψ–≥–Ψ ―²–Β–Φ–Α―²–Η―΅–Β―¹–Κ–Ψ–≥–Ψ –Φ–Ψ–¥–Β–Μ–Η―Ä–Ψ–≤–Α–Ϋ–Η―è // –€–Α―à–Η–Ϋ–Ϋ–Ψ–Β –Ψ–±―É―΅–Β–Ϋ–Η–Β –Η –Α–Ϋ–Α–Μ–Η–Ζ –¥–Α–Ϋ–Ϋ―΄―Ö. 2013. T. 1, ⳕ 6. –Γ. 657-686. –£–Β―Ä–Ψ―è―²–Ϋ–Ψ―¹―²–Ϋ–Α―è ―²–Β–Φ–Α―²–Η―΅–Β―¹–Κ–Α―è –Φ–Ψ–¥–Β–Μ―¨ ―¹―²―Ä–Ψ–Η―² –Η–Ϋ―²–Β―Ä–Ω―Ä–Β―²–Η―Ä―É–Β–Φ–Ψ–Β –Ω―Ä–Β–¥―¹―²–Α–≤–Μ–Β–Ϋ–Η–Β –Κ–Ψ–Μ–Μ–Β–Κ―Ü–Η–Η ―²–Β–Κ―¹―²–Ψ–≤―΄―Ö –¥–Ψ–Κ―É–Φ–Β–Ϋ―²–Ψ–≤, –Ψ–Ω–Η―¹―΄–≤–Α―è –Κ–Α–Ε–¥―΄–Ι –¥–Ψ–Κ―É–Φ–Β–Ϋ―² –¥–Η―¹–Κ―Ä–Β―²–Ϋ―΄–Φ ―Ä–Α―¹–Ω―Ä–Β–¥–Β–Μ–Β–Ϋ–Η–Β–Φ –Ϋ–Α –Φ–Ϋ–Ψ-–Ε–Β―¹―²–≤–Β ―²–Β–Φ, –Κ–Α–Ε–¥―É―é ―²–Β–Φ―É βÄî –¥–Η―¹–Κ―Ä–Β―²–Ϋ―΄–Φ ―Ä–Α―¹–Ω―Ä–Β–¥–Β–Μ–Β–Ϋ–Η–Β–Φ –Ϋ–Α –Φ–Ϋ–Ψ–Ε–Β―¹―²–≤–Β ―²–Β―Ä–Φ–Η–Ϋ–Ψ–≤. –†–Α―¹―¹–Φ–Α―²―Ä–Η–≤–Α–Β―²―¹―è –Ψ–±–Ψ–±―â―ë–Ϋ–Ϋ―΄–Ι EM-–Α–Μ–≥–Ψ―Ä–Η―²–Φ ―¹ ―ç–≤―Ä–Η―¹―²–Η–Κ–Α–Φ–Η ―¹–≥–Μ–Α–Ε–Η–≤–Α–Ϋ–Η―è, ―¹―ç–Φ–Ω–Μ–Η―Ä–Ψ–≤–Α–Ϋ–Η―è, ―Ä–Ψ–±–Α―¹―²–Ϋ–Ψ―¹―²–Η –Η ―Ä–Α–Ζ―Ä–Β–Ε–Η–≤–Α–Ϋ–Η―è, –Ω–Ψ–Ζ–≤–Ψ–Μ―è―é―â–Η–Ι –Ω―Ä–Η ―Ä–Α–Ζ–Μ–Η―΅–Ϋ―΄―Ö ―¹–Ψ―΅–Β―²–Α–Ϋ–Η―è―Ö ―ç―²–Η―Ö ―ç–≤―Ä–Η―¹―²–Η–Κ –Ω–Ψ–Μ―É―΅–Α―²―¨ –Κ–Α–Κ –Η–Ζ–≤–Β―¹―²–Ϋ―΄–Β ―²–Β–Φ–Α―²–Η―΅–Β―¹–Κ–Η–Β –Φ–Ψ–¥–Β–Μ–Η PLSA, LDA, SWB, ―²–Α–Κ –Η –Ϋ–Ψ–≤―΄–Β. –ü―Ä–Β–¥–Μ–Α–≥–Α–Β―²―¹―è―É–Ω―Ä–Ψ―â―ë–Ϋ–Ϋ―΄–Ι ―Ä–Ψ–±–Α―¹―²–Ϋ―΄–Ι –Α–Μ–≥–Ψ―Ä–Η―²–Φ, –Κ–Ψ―²–Ψ―Ä―΄–Ι –Ϋ–Β ―²―Ä–Β–±―É–Β―² –Ϋ–Η –¥–Ψ–Ω–Ψ–Μ–Ϋ–Η―²–Β–Μ―¨–Ϋ―΄―Ö –≤―΄―΅–Η―¹–Μ–Η―²–Β–Μ―¨–Ϋ―΄―Ö –Ζ–Α―²―Ä–Α―², –Ϋ–Η ―Ö―Ä–Α–Ϋ–Β–Ϋ–Η―è –Φ–Α―²―Ä–Η―Ü―΄ –Ω–Α―Ä–Α–Φ–Β―²―Ä–Ψ–≤ ―à―É–Φ–Α, –Η ―Ö–Ψ―Ä–Ψ―à–Ψ ―¹–Ψ―΅–Β―²–Α–Β―²―¹―è ―¹ ―ç–≤―Ä–Η―¹―²–Η–Κ–Ψ–Ι ―Ä–Α–Ζ―Ä–Β–Ε–Η–≤–Α–Ϋ–Η―è. –£ ―ç–Κ―¹–Ω–Β―Ä–Η–Φ–Β–Ϋ―²–Α―Ö –Ϋ–Α –¥–≤―É―Ö –Κ–Ψ–Μ–Μ–Β–Κ―Ü–Η―è―Ö –Ϋ–Α―É―΅–Ϋ―΄―Ö –Ω―É–±–Μ–Η–Κ–Α―Ü–Η–Ι, –Α–Ϋ–≥–Μ–Ψ―è–Ζ―΄―΅–Ϋ–Ψ–Ι –Η ―Ä―É―¹―¹–Κ–Ψ―è–Ζ―΄―΅–Ϋ–Ψ–Ι, –Ω–Ψ–¥–±–Η―Ä–Α―é―²―¹―è –Ψ–Ω―²–Η–Φ–Α–Μ―¨–Ϋ―΄–Β ―¹–Ψ―΅–Β―²–Α–Ϋ–Η―è ―¹―²―Ä–Α―²–Β–≥–Η–Ι ―Ä–Α–Ζ―Ä–Β–Ε–Η–≤–Α–Ϋ–Η―è –Η –¥―Ä―É–≥–Η―Ö ―ç–≤―Ä–Η―¹―²–Η–Κ. –ü–Ψ–Κ–Α–Ζ―΄–≤–Α–Β―²―¹―è, ―΅―²–Ψ ―Ä–Ψ–±–Α―¹―²–Ϋ–Α―è –Φ–Ψ–¥–Β–Μ―¨ –±–Β–Ζ ―¹–≥–Μ–Α–Ε–Η–≤–Α–Ϋ–Η―è –Ω–Ψ–Ζ–≤–Ψ–Μ―è–Β―² ―Ä–Α–Ζ―Ä–Β–Ε–Η–≤–Α―²―¨ –Η―¹–Κ–Ψ–Φ―΄–Β ―Ä–Α―¹–Ω―Ä–Β–¥–Β–Μ–Β–Ϋ–Η―è –Ϋ–Α 99% –±–Β–Ζ ―É―Ö―É–¥―à–Β–Ϋ–Η―è –Κ–Α―΅–Β―¹―²–≤–Α (–Ω–Β―Ä–Ω–Μ–Β–Κ―¹–Η–Η) –Φ–Ψ–¥–Β–Μ–Η.
–€–Α–Ϋ–Η–Μ–Ψ –¦.–ê., –ù–Β–Φ–Η―Ä–Κ–Ψ –ê.–ü., –Γ–Α–Μ–Α–Φ–Ψ–Ϋ–Ψ–≤–Α –‰.–Γ. –ê–≤―²–Ψ–Φ–Α―²–Η―΅–Β―¹–Κ–Η–Ι –Α–Ϋ–Α–Μ–Η–Ζ ―³–Ψ―Ä–Φ―΄ ―¹–Ω–Η―Ä–Ψ–≥―Ä–Α―³–Η―΅–Β―¹–Κ–Η―Ö –Ω–Β―²–Β–Μ―¨ // –€–Α―à–Η–Ϋ–Ϋ–Ψ–Β –Ψ–±―É―΅–Β–Ϋ–Η–Β –Η –Α–Ϋ–Α–Μ–Η–Ζ –¥–Α–Ϋ–Ϋ―΄―Ö. 2013. T. 1, ⳕ 6. –Γ. 687-694. –†–Α―¹―¹–Φ–Ψ―²―Ä–Β–Ϋ―΄ –Φ–Β―²–Ψ–¥―΄ –Α–≤―²–Ψ–Φ–Α―²–Η―΅–Β―¹–Κ–Ψ–≥–Ψ –Α–Ϋ–Α–Μ–Η–Ζ–Α ―¹–Ω–Η―Ä–Ψ–≥―Ä–Α―³–Η―΅–Β―¹–Κ–Η―Ö –Ω–Β―²–Β–Μ―¨ –≤~―É―¹–Μ–Ψ–≤–Η―è―Ö –Η―¹–Κ―É―¹―¹―²–≤–Β–Ϋ–Ϋ–Ψ–Ι –≤–Β–Ϋ―²–Η–Μ―è―Ü–Η–Η –Μ–Β–≥–Κ–Η―Ö. –ü―Ä–Ψ–≤–Β–¥–Β–Ϋ –Α–Ϋ–Α–Μ–Η–Ζ ―Ä–Α–Ζ–Μ–Η―΅–Ϋ―΄―Ö ―΅–Η―¹–Μ–Ψ–≤―΄―Ö ―Ö–Α―Ä–Α–Κ―²–Β―Ä–Η―¹―²–Η–Κ –Ω–Β―²–Β–Μ―¨ <<–Ψ–±―ä–Β–Φ-–¥–Α–≤–Μ–Β–Ϋ–Η–Β>>, –Ω–Ψ–Μ―É―΅–Β–Ϋ–Ϋ―΄―Ö –Ω–Ψ ―¹–Η–≥–Ϋ–Α―²―É―Ä–Β –¥–≤―É–Φ–Β―Ä–Ϋ―΄―Ö –Κ―Ä–Η–≤―΄―Ö. –ü–Ψ–Κ–Α–Ζ–Α–Ϋ―΄ –≤–Ψ–Ζ–Φ–Ψ–Ε–Ϋ–Ψ―¹―²–Η –Ω―Ä–Η–Φ–Β–Ϋ–Β–Ϋ–Η―è –¥–Η–Ϋ–Α–Φ–Η―΅–Β―¹–Κ–Ψ–≥–Ψ –Α–Ϋ–Α–Μ–Η–Ζ–Α ―¹–Ω–Η―Ä–Ψ–≥―Ä–Α–Φ–Φ –¥–Μ―è –Ψ―Ü–Β–Ϋ–Κ–Η –Ω–Α―Ä–Α–Φ–Β―²―Ä–Ψ–≤ –≤–Β–Ϋ―²–Η–Μ―è―Ü–Η–Η –Μ–Β–≥–Κ–Η―Ö –Η ―Ä–Α–Ϋ–Ϋ–Β–Ι –¥–Η–Α–≥–Ϋ–Ψ―¹―²–Η–Κ–Η –Ω–Α―²–Ψ–Μ–Ψ–≥–Η–Ι.
–ß―É–≤–Η–Μ–Η–Ϋ–Α –ï.–£. –‰–Ϋ―³–Ψ―Ä–Φ–Α―²–Η–≤–Ϋ–Ψ―¹―²―¨ –Ω―Ä–Η–Ζ–Ϋ–Α–Κ–Ψ–≤ –¥–Μ―è –¥–Η–Α–≥–Ϋ–Ψ―¹―²–Η–Κ–Η ―¹–Ψ―¹―²–Ψ―è–Ϋ–Η―è –Ω–Ψ–¥―à–Η–Ω–Ϋ–Η–Κ–Ψ–≤ –Ϋ–Α –Ψ―¹–Ϋ–Ψ–≤–Β –Ψ–±–Ϋ–Α―Ä―É–Ε–Β–Ϋ–Η―è –Μ–Ψ–Κ–Α–Μ―¨–Ϋ―΄―Ö –Ϋ–Β–Ψ–¥–Ϋ–Ψ―Ä–Ψ–¥–Ϋ–Ψ―¹―²–Β–Ι // –€–Α―à–Η–Ϋ–Ϋ–Ψ–Β –Ψ–±―É―΅–Β–Ϋ–Η–Β –Η –Α–Ϋ–Α–Μ–Η–Ζ –¥–Α–Ϋ–Ϋ―΄―Ö. 2013. T. 1, ⳕ 6. –Γ. 695-704. –†–Α―¹―¹–Φ–Α―²―Ä–Η–≤–Α–Β―²―¹―è –Ζ–Α–¥–Α―΅–Α –¥–Η–Α–≥–Ϋ–Ψ―¹―²–Η–Κ–Η ―¹–Ψ―¹―²–Ψ―è–Ϋ–Η―è –Ω–Ψ–¥―à–Η–Ω–Ϋ–Η–Κ–Ψ–≤ –™–Δ–î –Κ–Α–Κ –Ζ–Α–¥–Α―΅–Α ―Ä–Α―¹–Ω–Ψ–Ζ–Ϋ–Α–≤–Α-–Ϋ–Η―è –Ψ–±―Ä–Α–Ζ–Ψ–≤ –Ϋ–Α –Ψ―¹–Ϋ–Ψ–≤–Β –Ψ–±–Ϋ–Α―Ä―É–Ε–Β–Ϋ–Η―è –Μ–Ψ–Κ–Α–Μ―¨–Ϋ―΄―Ö –Ϋ–Β–Ψ–¥–Ϋ–Ψ―Ä–Ψ–¥–Ϋ–Ψ―¹―²–Β–Ι –≤ –≤–Η–±―Ä–Ψ―¹–Η–≥–Ϋ–Α–Μ–Β. –ü―Ä–Β–¥–Μ–Ψ-–Ε–Β–Ϋ―΄ –Η –Η―¹―¹–Μ–Β–¥–Ψ–≤–Α–Ϋ―΄ ―Ä―è–¥ –Ω―Ä–Η–Ζ–Ϋ–Α–Κ–Ψ–≤―΄―Ö –Ω―Ä–Ψ―¹―²―Ä–Α–Ϋ―¹―²–≤, –≤―΄–¥–Β–Μ–Β–Ϋ―΄ –Ϋ–Α–Η–±–Ψ–Μ–Β–Β –Η–Ϋ―³–Ψ―Ä–Φ–Α―²–Η–≤–Ϋ―΄–Β –Η–Ζ –Ϋ–Η―Ö, –Η–Φ–Β―é―â–Η–Β –Μ–Η–Ϋ–Β–Ι–Ϋ―É―é ―Ä–Α–Ζ–¥–Β–Μ–Η–Φ–Ψ―¹―²―¨, –Α –Η–Φ–Β–Ϋ–Ϋ–Ψ: –Η–Ζ–Φ–Β–Ϋ–Β–Ϋ–Η–Β ―³―Ä–Α–Κ―²–Α–Μ―¨–Ϋ–Ψ–Ι ―Ä–Α–Ζ–Φ–Β―Ä–Ϋ–Ψ―¹―²–Η, –≤–Β–Κ―²–Ψ―Ä―΄ –Κ–Ψ―ç―³―³–Η―Ü–Η–Β–Ϋ―²–Ψ–≤ ―¹–Ϋ–Ψ―¹–Α, –Φ–Α―²―Ä–Η―Ü―΄ –Ζ–Α–≤–Η―¹–Η–Φ–Ψ―¹―²–Η –Ω―Ä–Η―Ä–Α―â–Β–Ϋ–Η―è –Ψ―² –≤–Β–Μ–Η―΅–Η–Ϋ―΄ ―¹–Η–≥–Ϋ–Α–Μ–Α.
–î―é–Κ–Ψ–≤–Α –ï.–£., –¦―é–±–Η–Φ―Ü–Β–≤–Α –€.–€., –ü―Ä–Ψ–Κ–Ψ―³―¨–Β–≤ –ü.–ê. –û–± –Α–Μ–≥–Β–±―Ä–Ψ-–Μ–Ψ–≥–Η―΅–Β―¹–Κ–Ψ–Ι –Κ–Ψ―Ä―Ä–Β–Κ―Ü–Η–Η –≤ –Ζ–Α–¥–Α―΅–Α―Ö ―Ä–Α―¹–Ω–Ψ–Ζ–Ϋ–Α–≤–Α–Ϋ–Η―è –Ω–Ψ –Ω―Ä–Β―Ü–Β–¥–Β–Ϋ―²–Α–Φ // –€–Α―à–Η–Ϋ–Ϋ–Ψ–Β –Ψ–±―É―΅–Β–Ϋ–Η–Β –Η –Α–Ϋ–Α–Μ–Η–Ζ –¥–Α–Ϋ–Ϋ―΄―Ö. 2013. T. 1, ⳕ 6. –Γ. 705-713. –‰―¹―¹–Μ–Β–¥―É―é―²―¹―è –Μ–Ψ–≥–Η―΅–Β―¹–Κ–Η–Β –Κ–Ψ―Ä―Ä–Β–Κ―²–Ψ―Ä―΄ βÄî –Φ–Ψ–¥–Β–Μ–Η ―Ä–Α―¹–Ω–Ψ–Ζ–Ϋ–Α―é―â–Η―Ö –Α–Μ–≥–Ψ―Ä–Η―²–Φ–Ψ–≤, –Ψ―¹–Ϋ–Ψ–≤–Α–Ϋ–Ϋ―΄–Β –Ϋ–Α –≥–Ψ–Μ–Ψ―¹–Ψ–≤–Α–Ϋ–Η–Η –Ω–Ψ –Κ–Ψ―Ä―Ä–Β–Κ―²–Ϋ―΄–Φ –Ϋ–Α–±–Ψ―Ä–Α–Φ ―ç–Μ–Β–Φ–Β–Ϋ―²–Α―Ä–Ϋ―΄―Ö –Κ–Μ–Α―¹―¹–Η―³–Η–Κ–Α―²–Ψ―Ä–Ψ–≤ (―ç–Μ.–Κ–Μ.). –£–≤–Ψ–¥–Η―²―¹―è –Ω–Ψ–Ϋ―è―²–Η–Β –Α–Ϋ―²–Η–Φ–Ψ–Ϋ–Ψ―²–Ψ–Ϋ–Ϋ–Ψ–≥–Ψ –Κ–Ψ―Ä―Ä–Β–Κ―²–Ϋ–Ψ–≥–Ψ –Ϋ–Α–±–Ψ―Ä–Α ―ç–Μ.–Κ–Μ. –ù–Α –±–Α–Ζ–Β –Α–Ϋ―²–Η–Φ–Ψ–Ϋ–Ψ―²–Ψ–Ϋ–Ϋ―΄―Ö –Κ–Ψ―Ä―Ä–Β–Κ―²-–Ϋ―΄―Ö –Ϋ–Α–±–Ψ―Ä–Ψ–≤ ―ç–Μ.–Κ–Μ. –Ω–Ψ―¹―²―Ä–Ψ–Β–Ϋ –Μ–Ψ–≥–Η―΅–Β―¹–Κ–Η–Ι –Κ–Ψ―Ä―Ä–Β–Κ―²–Ψ―Ä. –ü―Ä–Η–≤–Β–¥–Β–Ϋ―΄ ―Ä–Β–Ζ―É–Μ―¨―²–Α―²―΄ ―²–Β―¹―²–Η―Ä–Ψ–≤–Α–Ϋ–Η―è –Ϋ–Ψ–≤–Ψ–Ι –Φ–Ψ–¥–Β–Μ–Η –Μ–Ψ–≥–Η―΅–Β―¹–Κ–Ψ–≥–Ψ –Κ–Ψ―Ä―Ä–Β–Κ―²–Ψ―Ä–Α –Ϋ–Α ―Ä–Β–Α–Μ―¨–Ϋ―΄―Ö –¥–Α–Ϋ–Ϋ–Ϋ―΄―Ö.
–ö―É–¥–Η–Ϋ–Ψ–≤ –€.–Γ. –ß–Α―¹―²–Η―΅–Ϋ―΄–Ι ―¹–Η–Ϋ―²–Α–Κ―¹–Η―΅–Β―¹–Κ–Η–Ι ―Ä–Α–Ζ–±–Ψ―Ä ―²–Β–Κ―¹―²–Α –Ϋ–Α ―Ä―É―¹―¹–Κ–Ψ–Φ ―è–Ζ―΄–Κ–Β ―¹ –Ω–Ψ–Φ–Ψ―â―¨―é ―É―¹–Μ–Ψ–≤–Ϋ―΄―Ö ―¹–Μ―É―΅–Α–Ι–Ϋ―΄―Ö –Ω–Ψ–Μ–Β–Ι // –€–Α―à–Η–Ϋ–Ϋ–Ψ–Β –Ψ–±―É―΅–Β–Ϋ–Η–Β –Η –Α–Ϋ–Α–Μ–Η–Ζ –¥–Α–Ϋ–Ϋ―΄―Ö. 2013. T. 1, ⳕ 6. Pp. 714-724. –£ ―¹―²–Α―²―¨–Β –Η–Ζ–Μ–Ψ–Ε–Β–Ϋ –Ω–Ψ–¥―Ö–Ψ–¥ –Κ –Ω–Ψ–Η―¹–Κ―É ―¹–Η–Ϋ―²–Α–Κ―¹–Η―΅–Β―¹–Κ–Η ―¹–≤―è–Ζ–Α–Ϋ–Ϋ―΄―Ö –≥―Ä―É–Ω–Ω ―¹–Ψ―¹–Β–¥–Ϋ–Η―Ö ―¹–Μ–Ψ–≤ (chunks) –≤ ―Ä―É―¹―¹–Κ–Ψ–Φ ―²–Β–Κ―¹―²–Β. –ü―Ä–Ψ–¥–Β–Φ–Ψ–Ϋ―¹―²―Ä–Η―Ä–Ψ–≤–Α–Ϋ–Α –Ω―Ä–Η–Ϋ―Ü–Η–Ω–Η–Α–Μ―¨–Ϋ–Α―è –≤–Ψ–Ζ–Φ–Ψ–Ε–Ϋ–Ψ―¹―²―¨ –Η –Κ–Ψ―Ä―Ä–Β–Κ―²–Ϋ–Ψ―¹―²―¨ –Ω–Ψ―¹―²–Α–Ϋ–Ψ–≤–Κ–Η –Ζ–Α–¥–Α―΅–Η –≤―΄–¥–Β–Μ–Β–Ϋ–Η―è ―²–Α–Κ–Η―Ö –≥―Ä―É–Ω–Ω –Ω―Ä–Η–Φ–Β–Ϋ–Η―²–Β–Μ―¨–Ϋ–Ψ –Κ ―è–Ζ―΄–Κ―É ―¹–Ψ ―¹–≤–Ψ–±–Ψ–¥–Ϋ―΄–Φ –Ω–Ψ―Ä―è–¥–Κ–Ψ–Φ ―¹–Μ–Ψ–≤. –Γ –Η―¹–Ω–Ψ–Μ―¨–Ζ–Ψ–≤–Α–Ϋ–Η–Β–Φ –Α–Ω–Ω–Α―Ä–Α―²–Α ―É―¹–Μ–Ψ–≤–Ϋ―΄―Ö ―¹–Μ―É―΅–Α–Ι–Ϋ―΄―Ö –Ω–Ψ–Μ–Β–Ι –Ψ–Ω―Ä–Β–¥–Β–Μ–Β–Ϋ–Ϋ―΄–Ι –Κ–Μ–Α―¹―¹ –Ω–Ψ–¥–Ψ–±–Ϋ―΄―Ö –≥―Ä―É–Ω–Ω –Φ–Ψ–Ε–Ϋ–Ψ –≤―΄–¥–Β–Μ–Η―²―¨ ―¹ 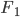 –Φ–Β―Ä–Ψ–Ι –Ϋ–Β –Φ–Β–Ϋ–Β–Β
–Φ–Β―Ä–Ψ–Ι –Ϋ–Β –Φ–Β–Ϋ–Β–Β 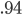 . –ü―Ä–Η ―ç―²–Ψ–Φ –Ψ–±―É―΅–Α―é―â–Α―è –≤―΄–±–Ψ―Ä–Κ–Α –Φ–Ψ–Ε–Β―² –±―΄―²―¨ –Ω–Ψ–Μ―É―΅–Β–Ϋ–Α –Ω―É―²–Β–Φ –Ψ–±―Ä–Α–±–Ψ―²–Κ–Η –Η―¹―Ö–Ψ–¥–Ϋ–Ψ–≥–Ψ ―²–Β–Κ―¹―²–Α ―¹–Η–Ϋ―²–Α–Κ―¹–Η―΅–Β―¹–Κ–Η–Φ –Α–Ϋ–Α–Μ–Η–Ζ–Α―²–Ψ―Ä–Ψ–Φ –±–Β–Ζ –Ω–Ψ―¹–Μ–Β–¥―É―é―â–Β–Ι ―Ä―É―΅–Ϋ–Ψ–Ι –Κ–Ψ―Ä―Ä–Β–Κ―Ü–Η–Η ―Ä–Β–Ζ―É–Μ―¨―²–Α―²–Ψ–≤. –Δ–Β–Φ –Ϋ–Β –Φ–Β–Ϋ–Β–Β, –≤―΄–¥–Β–Μ–Β–Ϋ–Η–Β –¥–Ψ―¹―²–Α―²–Ψ―΅–Ϋ–Ψ –¥–Μ–Η–Ϋ–Ϋ―΄―Ö ―³―Ä–Α–≥–Φ–Β–Ϋ―²–Ψ–≤ ―²–Β–Κ―¹―²–Α –Ψ–Κ–Α–Ζ―΄–≤–Α–Β―²―¹―è –Ζ–Α―²―Ä―É–¥–Ϋ–Η―²–Β–Μ―¨–Ϋ―΄–Φ, –Α –Ω–Ψ–Κ–Α–Ζ–Α―²–Β–Μ―¨ –Φ–Β―Ä―΄, –Ω–Ψ–Μ―É―΅–Β–Ϋ–Ϋ―΄–Ι –≤ ―ç–Κ―¹–Ω–Β―Ä–Η–Φ–Β–Ϋ―²–Β, –¥–Ψ―¹―²–Α―²–Ψ―΅–Ϋ–Ψ –Ϋ–Η–Ζ–Κ–Η–Φ.
. –ü―Ä–Η ―ç―²–Ψ–Φ –Ψ–±―É―΅–Α―é―â–Α―è –≤―΄–±–Ψ―Ä–Κ–Α –Φ–Ψ–Ε–Β―² –±―΄―²―¨ –Ω–Ψ–Μ―É―΅–Β–Ϋ–Α –Ω―É―²–Β–Φ –Ψ–±―Ä–Α–±–Ψ―²–Κ–Η –Η―¹―Ö–Ψ–¥–Ϋ–Ψ–≥–Ψ ―²–Β–Κ―¹―²–Α ―¹–Η–Ϋ―²–Α–Κ―¹–Η―΅–Β―¹–Κ–Η–Φ –Α–Ϋ–Α–Μ–Η–Ζ–Α―²–Ψ―Ä–Ψ–Φ –±–Β–Ζ –Ω–Ψ―¹–Μ–Β–¥―É―é―â–Β–Ι ―Ä―É―΅–Ϋ–Ψ–Ι –Κ–Ψ―Ä―Ä–Β–Κ―Ü–Η–Η ―Ä–Β–Ζ―É–Μ―¨―²–Α―²–Ψ–≤. –Δ–Β–Φ –Ϋ–Β –Φ–Β–Ϋ–Β–Β, –≤―΄–¥–Β–Μ–Β–Ϋ–Η–Β –¥–Ψ―¹―²–Α―²–Ψ―΅–Ϋ–Ψ –¥–Μ–Η–Ϋ–Ϋ―΄―Ö ―³―Ä–Α–≥–Φ–Β–Ϋ―²–Ψ–≤ ―²–Β–Κ―¹―²–Α –Ψ–Κ–Α–Ζ―΄–≤–Α–Β―²―¹―è –Ζ–Α―²―Ä―É–¥–Ϋ–Η―²–Β–Μ―¨–Ϋ―΄–Φ, –Α –Ω–Ψ–Κ–Α–Ζ–Α―²–Β–Μ―¨ –Φ–Β―Ä―΄, –Ω–Ψ–Μ―É―΅–Β–Ϋ–Ϋ―΄–Ι –≤ ―ç–Κ―¹–Ω–Β―Ä–Η–Φ–Β–Ϋ―²–Β, –¥–Ψ―¹―²–Α―²–Ψ―΅–Ϋ–Ψ –Ϋ–Η–Ζ–Κ–Η–Φ.
–¦–Α–Ϋ–≥–Β –€.–€, –™–Α–Ϋ–Β–±–Ϋ―΄―Ö –Γ.–ù. –‰–Β―Ä–Α―Ä―Ö–Η―΅–Β―¹–Κ–Η–Β ―¹―²―Ä―É–Κ―²―É―Ä―΄ –¥–Α–Ϋ–Ϋ―΄―Ö –Η ―Ä–Β―à–Α―é―â–Η–Β –Α–Μ–≥–Ψ―Ä–Η―²–Φ―΄ –¥–Μ―è –Κ–Μ–Α―¹―¹–Η―³–Η–Κ–Α―Ü–Η–Η –Η–Ζ–Ψ–±―Ä–Α–Ε–Β–Ϋ–Η–Ι // –€–Α―à–Η–Ϋ–Ϋ–Ψ–Β –Ψ–±―É―΅–Β–Ϋ–Η–Β –Η –Α–Ϋ–Α–Μ–Η–Ζ –¥–Α–Ϋ–Ϋ―΄―Ö. 2013. T. 1, ⳕ 6. –Γ. 725-733. –‰―¹―¹–Μ–Β–¥―É–Β―²―¹―è –Ζ–Α–¥–Α―΅–Α –Κ–Μ–Α―¹―¹–Η―³–Η–Κ–Α―Ü–Η–Η –Ψ–±―ä–Β–Κ―²–Ψ–≤, –Ζ–Α–¥–Α–Ϋ–Ϋ―΄―Ö –Η–Ζ–Ψ–±―Ä–Α–Ε–Β–Ϋ–Η―è–Φ–Η, –≤ ―²–Β―Ä–Φ–Η–Ϋ–Α―Ö ―¹–Ψ–Ψ―²–Ϋ–Ψ―à–Β–Ϋ–Η―è –≤―΄―΅–Η―¹–Μ–Η―²–Β–Μ―¨–Ϋ–Ψ–Ι ―¹–Μ–Ψ–Ε–Ϋ–Ψ―¹―²–Η –Η –≤–Β―Ä–Ψ―è―²–Ϋ–Ψ―¹―²–Η –Ψ―à–Η–±–Κ–Η. –‰―¹–Ω–Ψ–Μ―¨–Ζ―É―è –Φ–Ϋ–Ψ–≥–Ψ―É―Ä–Ψ–≤–Ϋ–Β–≤―É―é ―¹–Β―²―¨ ―ç―²–Α–Μ–Ψ–Ϋ–Ψ–≤, –Ω―Ä–Β–¥–Μ–Α–≥–Α―é―²―¹―è –Α–Μ–≥–Ψ―Ä–Η―²–Φ―΄ –Η–Β―Ä–Α―Ä―Ö–Η―΅–Β―¹–Κ–Ψ–≥–Ψ –Ω–Ψ–Η―¹–Κ–Α ―Ä–Β―à–Β–Ϋ–Η―è –Ω–Ψ –Κ―Ä–Η―²–Β―Ä–Η―é –±–Μ–Η–Ε–Α–Ι―à–Β–≥–Ψ ―ç―²–Α–Μ–Ψ–Ϋ–Α. –ü–Ψ–Μ―É―΅–Β–Ϋ―΄ ―¹―Ä–Α–≤–Ϋ–Η―²–Β–Μ―¨–Ϋ―΄–Β –Ψ―Ü–Β–Ϋ–Κ–Η –≤―΄―΅–Η―¹–Μ–Η―²–Β–Μ―¨–Ϋ–Ψ–Ι ―¹–Μ–Ψ–Ε–Ϋ–Ψ―¹―²–Η –Η–Β―Ä–Α―Ä―Ö–Η―΅–Β―¹–Κ–Η―Ö –Α–Μ–≥–Ψ―Ä–Η―²–Φ–Ψ–≤ –Ψ―²–Ϋ–Ψ―¹–Η―²–Β–Μ―¨–Ϋ–Ψ –Α–Μ–≥–Ψ―Ä–Η―²–Φ–Α –Ω–Ψ–Μ–Ϋ–Ψ–≥–Ψ –Ω–Β―Ä–Β–±–Ψ―Ä–Α ―ç―²–Α–Μ–Ψ–Ϋ–Ψ–≤. –ü―Ä–Η–≤–Β–¥–Β–Ϋ―΄ ―ç–Κ―¹–Ω–Β―Ä–Η–Φ–Β–Ϋ―²–Α–Μ―¨–Ϋ―΄–Β –Ζ–Α–≤–Η―¹–Η–Φ–Ψ―¹―²–Η –≤―΄―΅–Η―¹–Μ–Η―²–Β–Μ―¨–Ϋ–Ψ–Ι ―¹–Μ–Ψ–Ε–Ϋ–Ψ―¹―²–Η –Ψ―² –≤–Β―Ä–Ψ―è―²–Ϋ–Ψ―¹―²–Η –Ψ―à–Η–±–Κ–Η ―Ä–Α―¹–Ω–Ψ–Ζ–Ϋ–Α–≤–Α–Ϋ–Η―è –Ω–Ψ–¥–Ω–Η―¹–Β–Ι, –Ε–Β―¹―²–Ψ–≤ –Η –Μ–Η―Ü –¥–Μ―è ―Ä–Β―à–Α―é―â–Η―Ö –Α–Μ–≥–Ψ―Ä–Η―²–Φ–Ψ–≤ –Ϋ–Α –Ψ―¹–Ϋ–Ψ–≤–Β –Η–Β―Ä–Α―Ä―Ö–Η―΅–Β―¹–Κ–Ψ–≥–Ψ –Ω–Ψ–Η―¹–Κ–Α –Η –Ω–Ψ–Μ–Ϋ–Ψ–≥–Ψ –Ω–Β―Ä–Β–±–Ψ―Ä–Α.
–£–Ψ―Ä–Ψ–Ϋ―Ü–Ψ–≤ –ö.–£., –Λ―Ä–Β–Ι –ê.–‰., –Γ–Ψ–Κ–Ψ–Μ–Ψ–≤ –ï.–ê. –£―΄―΅–Η―¹–Μ–Η–Φ―΄–Β –Κ–Ψ–Φ–±–Η–Ϋ–Α―²–Ψ―Ä–Ϋ―΄–Β –Ψ―Ü–Β–Ϋ–Κ–Η –≤–Β―Ä–Ψ―è―²–Ϋ–Ψ―¹―²–Η –Ω–Β―Ä–Β–Ψ–±―É―΅–Β–Ϋ–Η―è // –€–Α―à–Η–Ϋ–Ϋ–Ψ–Β –Ψ–±―É―΅–Β–Ϋ–Η–Β –Η –Α–Ϋ–Α–Μ–Η–Ζ –¥–Α–Ϋ–Ϋ―΄―Ö. 2013. T. 1, ⳕ 6. –Γ. 734-743. –£ –¥–Α–Ϋ–Ϋ–Ψ–Ι ―¹―²–Α―²―¨–Β –Η–Ζ―É―΅–Α―é―²―¹―è –Κ–Ψ–Φ–±–Η–Ϋ–Α―²–Ψ―Ä–Ϋ―΄–Β –Ψ―Ü–Β–Ϋ–Κ–Η –Ψ–±–Ψ–±―â–Α―é―â–Β–Ι ―¹–Ω–Ψ―¹–Ψ–±–Ϋ–Ψ―¹―²–Η, –≤―΄―΅–Η―¹–Μ–Η–Φ―΄–Β –Ω–Ψ –Ψ–±―É―΅–Α―é―â–Β–Ι –≤―΄–±–Ψ―Ä–Κ–Β. –≠―²–Η –Ψ―Ü–Β–Ϋ–Κ–Η –Ψ―¹–Ϋ–Ψ–≤–Α–Ϋ―΄ –Ϋ–Α ―É–Ω―Ä–Ψ―â–Β–Ϋ–Ϋ–Ψ–Ι –≤–Β―Ä–Ψ―è―²–Ϋ–Ψ―¹―²–Ϋ–Ψ–Ι –Φ–Ψ–¥–Β–Μ–Η, –≤ –Κ–Ψ―²–Ψ―Ä–Ψ–Ι ―Ä–Α―¹―¹–Φ–Α―²―Ä–Η–≤–Α–Β―²―¹―è –Μ–Η―à―¨ –Κ–Ψ–Ϋ–Β―΅–Ϋ–Α―è –≥–Β–Ϋ–Β―Ä–Α–Μ―¨–Ϋ–Α―è ―¹–Ψ–≤–Ψ–Κ―É–Ω–Ϋ–Ψ―¹―²―¨ –Ψ–±―ä–Β–Κ―²–Ψ–≤ –Η –±–Η–Ϋ–Α―Ä–Ϋ–Α―è ―³―É–Ϋ–Κ―Ü–Η―è –Ω–Ψ―²–Β―Ä―¨. –î–Μ―è –Μ–Η–Ϋ–Β–Ι–Ϋ―΄―Ö –Κ–Μ–Α―¹―¹–Η―³–Η–Κ–Α―²–Ψ―Ä–Ψ–≤ –Ω―Ä–Β–¥–Μ–Α–≥–Α–Β―²―¹―è –Ϋ–Ψ–≤―΄–Ι ―ç―³―³–Β–Κ―²–Η–≤–Ϋ―΄–Ι –Φ–Β―²–Ψ–¥ –≤―΄―΅–Η―¹–Μ–Β–Ϋ–Η―è –Κ–Ψ–Φ–±–Η–Ϋ–Α―²–Ψ―Ä–Ϋ―΄―Ö –Ψ―Ü–Β–Ϋ–Ψ–Κ, –Η―¹–Ω–Ψ–Μ―¨–Ζ―É―é―â–Η–Ι ―¹–Μ―É―΅–Α–Ι–Ϋ―΄–Β –±–Μ―É–Ε–¥–Α–Ϋ–Η–Ι –Ω–Ψ –Φ–Ϋ–Ψ–Ε–Β―¹―²–≤―É –Κ–Μ–Α―¹―¹–Η―³–Η–Κ–Α―²–Ψ―Ä–Ψ–≤ ―¹ –Ϋ–Η–Ζ–Κ–Η–Φ ―΅–Η―¹–Μ–Ψ–Φ –Ψ―à–Η–±–Ψ–Κ. –£ –Ζ–Α–Κ–Μ―é―΅–Β–Ϋ–Η–Η –Ω―Ä–Η–≤–Ψ–¥–Η―²―¹―è ―ç–Κ―¹–Ω–Β―Ä–Η–Φ–Β–Ϋ―²–Α–Μ―¨–Ϋ–Ψ–Β –Ψ–±–Ψ―¹–Ϋ–Ψ–≤–Α–Ϋ–Η–Β –Ω―Ä–Β–¥–Μ–Α–≥–Α–Β–Φ–Ψ–≥–Ψ –Φ–Β―²–Ψ–¥–Α.
–†–Α–Ζ–Η–Ϋ –ù.–ê., –€–Ψ―²―²–Μ―¨ –£.–£. –ß–Η―¹–Μ–Β–Ϋ–Ϋ–Α―è ―Ä–Β–Α–Μ–Η–Ζ–Α―Ü–Η―è –Α–Μ–≥–Ψ―Ä–Η―²–Φ–Ψ–≤ ―¹–Β–Μ–Β–Κ―²–Η–≤–Ϋ–Ψ–≥–Ψ –Κ–Ψ–Φ–±–Η–Ϋ–Η―Ä–Ψ–≤–Α–Ϋ–Η―è ―Ä–Α–Ζ–Ϋ–Ψ―Ä–Ψ–¥–Ϋ―΄―Ö –Ω―Ä–Β–¥―¹―²–Α–≤–Μ–Β–Ϋ–Η–Ι –Ψ–±―ä–Β–Κ―²–Ψ–≤ –≤ –Ζ–Α–¥–Α―΅–Α―Ö ―Ä–Α―¹–Ω–Ψ–Ζ–Ϋ–Α–≤–Α–Ϋ–Η―è –Ψ–±―Ä–Α–Ζ–Ψ–≤ // –€–Α―à–Η–Ϋ–Ϋ–Ψ–Β –Ψ–±―É―΅–Β–Ϋ–Η–Β –Η –Α–Ϋ–Α–Μ–Η–Ζ –¥–Α–Ϋ–Ϋ―΄―Ö. 2013. T. 1, ⳕ 6. –Γ. 744-760. –£ ―Ä–Α–±–Ψ―²–Β ―Ä–Α―¹―¹–Φ–Α―²―Ä–Η–≤–Α―é―²―¹―è –Φ–Β―²–Ψ–¥―΄ ―Ä–Β―à–Β–Ϋ–Η―è –Ζ–Α–¥–Α―΅ –±–Β―¹–Ω―Ä–Η–Ζ–Ϋ–Α–Κ–Ψ–≤–Ψ–≥–Ψ ―Ä–Α―¹–Ω–Ψ–Ζ–Ϋ–Α–≤–Α–Ϋ–Η―è –Ψ–±―Ä–Α–Ζ–Ψ–≤ –≤ –Ω―Ä–Β–¥–Ω–Ψ–Μ–Ψ–Ε–Β–Ϋ–Η–Η, ―΅―²–Ψ –Ψ–±―ä–Β–Κ―²―΄ –Ω–Ψ–Ω–Α―Ä–Ϋ–Ψ ―¹―Ä–Α–≤–Ϋ–Η–≤–Α―é―²―¹―è –Ω―Ä–Η –Ω–Ψ–Φ–Ψ―â–Η –Ω―Ä–Ψ–Η–Ζ–≤–Ψ–Μ―¨–Ϋ–Ψ–Ι –¥–Β–Ι―¹―²–≤–Η―²–Β–Μ―¨–Ϋ–Ψ–Ι ―³―É–Ϋ–Κ―Ü–Η–Η. –Δ–Α–Κ–Ψ–Ι –Ω–Ψ–¥―Ö–Ψ–¥ ―è–≤–Μ―è–Β―²―¹―è –≥–Ψ―Ä–Α–Ζ–¥–Ψ –±–Ψ–Μ–Β–Β –Ψ–±―â–Η–Φ, ―΅–Β–Φ ―²―Ä–Α–¥–Η―Ü–Η–Ψ–Ϋ–Ϋ―΄–Ι –Φ–Β―²–Ψ–¥ –Ω–Ψ―²–Β–Ϋ―Ü–Η–Α–Μ―¨–Ϋ―΄―Ö ―³―É–Ϋ–Κ―Ü–Η–Ι (–Κ–Β―Ä–Ϋ–Β–Μ–Ψ–≤), ―²―Ä–Β–±―É―é―â–Η–Ι –Ω–Ψ–Μ–Ψ–Ε–Η―²–Β–Μ―¨–Ϋ–Ψ–Ι –Ω–Ψ–Μ―É–Ψ–Ω―Ä–Β–¥–Β–Μ–Β–Ϋ–Ϋ–Ψ―¹―²–Η –Φ–Α―²―Ä–Η―Ü―΄ ―³―É–Ϋ–Κ―Ü–Η–Η ―¹―Ä–Α–≤–Ϋ–Β–Ϋ–Η―è –Ψ–±―ä–Β–Κ―²–Ψ–≤. –£–Α–Ε–Ϋ–Ψ–Β –Ω―Ä–Β–Η–Φ―É―â–Β―¹―²–≤–Ψ –Ω―Ä–Β–¥–Μ–Α–≥–Α–Β–Φ―΄―Ö –Α–Μ–≥–Ψ―Ä–Η―²–Φ–Ψ–≤ –Ω–Β―Ä–Β–¥ ―¹―É―â–Β―¹―²–≤―É―é―â–Η–Φ–Η –Ζ–Α–Κ–Μ―é―΅–Α–Β―²―¹―è –≤ ―²–Ψ–Φ, ―΅―²–Ψ –Ψ–Ϋ–Η ―Ö–Ψ―Ä–Ψ―à–Ψ ―Ä–Α―¹–Ω–Α―Ä–Α–Μ–Μ–Β–Μ–Η–≤–Α―é―²―¹―è –Ϋ–Α ―¹–Ψ–≤―Ä–Β–Φ–Β–Ϋ–Ϋ―΄―Ö –Φ–Ϋ–Ψ–≥–Ψ–Ω―Ä–Ψ―Ü–Β―¹―¹–Ψ―Ä–Ϋ―΄―Ö –≤―΄―΅–Η―¹–Μ–Η―²–Β–Μ―¨–Ϋ―΄―Ö ―¹–Η―¹―²–Β–Φ–Α―Ö, ―΅―²–Ψ –Ω–Ψ–Ζ–≤–Ψ–Μ―è–Β―² –Η―¹–Ω–Ψ–Μ―¨–Ζ–Ψ–≤–Α―²―¨ –Φ–Ψ―â–Ϋ―΄–Β –Κ–Μ–Α―¹―²–Β―Ä―΄ –¥–Μ―è –±―΄―¹―²―Ä–Ψ–≥–Ψ ―Ä–Β―à–Β–Ϋ–Η―è –Ζ–Α–¥–Α―΅ ―¹ –±–Ψ–Μ―¨―à–Η–Φ –Ψ–±―ä―ë–Φ–Ψ–Φ –¥–Α–Ϋ–Ϋ―΄―Ö. –ü–Ψ–Μ―É―΅–Β–Ϋ–Ϋ–Ψ–Β ―É―¹–Κ–Ψ―Ä–Β–Ϋ–Η–Β –Ω–Ψ ―¹―Ä–Α–≤–Ϋ–Β–Ϋ–Η―é ―¹ –Ϋ–Α–Η–≤–Ϋ―΄–Φ–Η ―Ä–Β–Α–Μ–Η–Ζ–Α―Ü–Η―è–Φ–Η –Α–Μ–≥–Ψ―Ä–Η―²–Φ–Ψ–≤ –¥–Ψ―Ö–Ψ–¥–Η―² –¥–Ψ 25 ―Ä–Α–Ζ –Ϋ–Α ―¹―Ä–Α–≤–Ϋ–Η―²–Β–Μ―¨–Ϋ–Ψ ―¹–Μ–Α–±–Ψ–Ι –Ω–Ψ –Φ–Ψ―â–Ϋ–Ψ―¹―²–Η –≤–Η–¥–Β–Ψ–Κ–Α―Ä―²–Β NVidia GeForce 310M.
–Λ―Ä–Β–Ι –ê.–‰., –Δ–Ψ–Μ―¹―²–Η―Ö–Η–Ϋ –‰.–û. –ö–Ψ–Φ–±–Η–Ϋ–Α―²–Ψ―Ä–Ϋ―΄–Β –Ψ―Ü–Β–Ϋ–Κ–Η –≤–Β―Ä–Ψ―è―²–Ϋ–Ψ―¹―²–Η –Ω–Β―Ä–Β–Ψ–±―É―΅–Β–Ϋ–Η―è –Ϋ–Α –Ψ―¹–Ϋ–Ψ–≤–Β –Κ–Μ–Α―¹―²–Β―Ä–Η–Ζ–Α―Ü–Η–Η –Η –Ω–Ψ–Κ―Ä―΄―²–Η–Ι –Φ–Ϋ–Ψ–Ε–Β―¹―²–≤–Α –Α–Μ–≥–Ψ―Ä–Η―²–Φ–Ψ–≤ // –€–Α―à–Η–Ϋ–Ϋ–Ψ–Β –Ψ–±―É―΅–Β–Ϋ–Η–Β –Η –Α–Ϋ–Α–Μ–Η–Ζ –¥–Α–Ϋ–Ϋ―΄―Ö. 2013. T. 1, ⳕ 6. C. 761-778. –£ –¥–Α–Ϋ–Ϋ–Ψ–Ι ―Ä–Α–±–Ψ―²–Β –Ω―Ä–Β–¥–Μ–Α–≥–Α–Β―²―¹―è –Ϋ–Ψ–≤–Α―è –Κ–Ψ–Φ–±–Η–Ϋ–Α―²–Ψ―Ä–Ϋ–Α―è –Ψ―Ü–Β–Ϋ–Κ–Α –≤–Β―Ä–Ψ―è―²–Ϋ–Ψ―¹―²–Η –Ω–Β―Ä–Β–Ψ–±―É―΅–Β–Ϋ–Η―è, ―É―΅–Η―²―΄–≤–Α―é―â–Α―è ―¹―Ö–Ψ–¥―¹―²–≤–Ψ –Α–Μ–≥–Ψ―Ä–Η―²–Φ–Ψ–≤.–û―Ü–Β–Ϋ–Κ–Α –Ψ―¹–Ϋ–Ψ–≤–Α–Ϋ–Α –Ϋ–Α ―Ä–Α–Ζ–Μ–Ψ–Ε–Β–Ϋ–Η–Η –Φ–Ϋ–Ψ–Ε–Β―¹―²–≤–Α –Α–Μ–≥–Ψ―Ä–Η―²–Φ–Ψ–≤ –Ϋ–Α –Ϋ–Β–Ω–Β―Ä–Β―¹–Β–Κ–Α―é―â–Η–Β―¹―è –Ω–Ψ–¥–Φ–Ϋ–Ψ–Ε–Β―¹―²–≤–Α (–Κ–Μ–Α―¹―²–Β―Ä―΄). –‰―²–Ψ–≥–Ψ–≤–Α―è –Ψ―Ü–Β–Ϋ–Κ–Α ―É―΅–Η―²―΄–≤–Α–Β―² ―¹―Ö–Ψ–¥―¹―²–≤–Ψ –Α–Μ–≥–Ψ―Ä–Η―²–Φ–Ψ–≤ –≤–Ϋ―É―²―Ä–Η –Κ–Α–Ε–¥–Ψ–≥–Ψ –Κ–Μ–Α―¹―²–Β―Ä–Α, –Η ―Ä–Α―¹―¹–Μ–Ψ–Β–Ϋ–Η–Β –Α–Μ–≥–Ψ―Ä–Η―²–Φ–Ψ–≤ –Ω–Ψ ―΅–Η―¹–Μ―É –Ψ―à–Η–±–Ψ–Κ –Φ–Β–Ε–¥―É –Κ–Μ–Α―¹―²–Β―Ä–Α–Φ–Η.–î–Μ―è –Ψ―Ü–Β–Ϋ–Κ–Η –≤–Β―Ä–Ψ―è―²–Ϋ–Ψ―¹―²–Η –Ω–Β―Ä–Β–Ψ–±―É―΅–Β–Ϋ–Η―è –Κ–Α–Ε–¥–Ψ–≥–Ψ –Κ–Μ–Α―¹―²–Β―Ä–Α –Ω―Ä–Β–¥–Μ–Α–≥–Α–Β―²―¹―è ―²–Β–Ψ―Ä–Β―²–Η–Κ–Ψ-–≥―Ä―É–Ω–Ω–Ψ–≤–Ψ–Ι –Ω–Ψ–¥―Ö–Ψ–¥, –Ψ―¹–Ϋ–Ψ–≤–Α–Ϋ–Ϋ―΄–Ι –Ϋ–Α ―É―΅–Β―²–Β ―¹–Η–Φ–Φ–Β―²―Ä–Η–Ι. –ù–Α –Ω―Ä–Η–Φ–Β―Ä–Β –Ζ–Α–¥–Α―΅ –Η–Ζ ―Ä–Β–Ω–Ψ–Ζ–Η―²–Ψ―Ä–Η―è UCI –Ω–Ψ–Κ–Α–Ζ–Α–Ϋ–Ψ, ―΅―²–Ψ –Ω―Ä–Β–¥–Μ–Α–≥–Α–Β–Φ―΄–Ι –Φ–Β―²–Ψ–¥ –≤ ―Ä―è–¥–Β ―¹–Μ―É―΅–Α–Β–≤ –¥–Α–Β―² –Φ–Β–Ϋ–Β–Β –Ζ–Α–≤―΄―à–Β–Ϋ–Ϋ―É―é –Ψ―Ü–Β–Ϋ–Κ―É –≤–Β―Ä–Ψ―è―²–Ϋ–Ψ―¹―²–Η –Ω–Β―Ä–Β–Ψ–±―É―΅–Β–Ϋ–Η―è –Ω–Ψ ―¹―Ä–Α–≤–Ϋ–Β–Ϋ–Η―é ―¹ –Η–Ζ–≤–Β―¹―²–Ϋ―΄–Φ–Η ―Ä–Α–Ϋ–Β–Β –Κ–Ψ–Φ–±–Η–Ϋ–Α―²–Ψ―Ä–Ϋ―΄–Φ–Η –Ψ―Ü–Β–Ϋ–Κ–Α–Φ–Η.
–€―É―Ä–Α―à–Ψ–≤ –î.–€., –ë–Β―Ä–Β–Ζ–Η–Ϋ –ê.–£., –‰–≤–Α–Ϋ–Ψ–≤–Α –ï.–°. –Λ–Ψ―Ä–Φ–Η―Ä–Ψ–≤–Α–Ϋ–Η–Β –Ω―Ä–Η–Ζ–Ϋ–Α–Κ–Ψ–≤–Ψ–≥–Ψ –Ψ–Ω–Η―¹–Α–Ϋ–Η―è ―³–Α–Κ―²―É―Ä―΄ –Κ–Α―Ä―²–Η–Ϋ // –€–Α―à–Η–Ϋ–Ϋ–Ψ–Β –Ψ–±―É―΅–Β–Ϋ–Η–Β –Η –Α–Ϋ–Α–Μ–Η–Ζ –¥–Α–Ϋ–Ϋ―΄―Ö. 2013. T. 1, ⳕ 6. C. 779-786. –†–Α―¹―¹–Φ–Α―²―Ä–Η–≤–Α–Β―²―¹―è –Ζ–Α–¥–Α―΅–Α ―³–Ψ―Ä–Φ–Η―Ä–Ψ–≤–Α–Ϋ–Η―è –Ω―Ä–Η–Ζ–Ϋ–Α–Κ–Ψ–≤–Ψ–≥–Ψ –Ω―Ä–Ψ―¹―²―Ä–Α–Ϋ―¹―²–≤–Α –¥–Μ―è ―¹―Ä–Α–≤–Ϋ–Β–Ϋ–Η―è –Η–Ζ–Ψ–±―Ä–Α–Ε–Β–Ϋ–Η–Ι –≤ –Α―²―Ä–Η–±―É―Ü–Η–Η –Ω―Ä–Ψ–Η–Ζ–≤–Β–¥–Β–Ϋ–Η–Ι –Ε–Η–≤–Ψ–Ω–Η―¹–Η. –ü―Ä–Β–¥–Μ–Ψ–Ε–Β–Ϋ–Ψ –Ω―Ä–Η–Ζ–Ϋ–Α–Κ–Ψ–≤–Ψ–Β –Ψ–Ω–Η―¹–Α–Ϋ–Η–Β ―³–Α–Κ―²―É―Ä―΄ –Κ–Α―Ä―²–Η–Ϋ –Ϋ–Α –Ψ―¹–Ϋ–Ψ–≤–Β ―Ö–Α―Ä–Α–Κ―²–Β―Ä–Η―¹―²–Η–Κ ―Ö―Ä–Β–±―²–Ψ–≤ –Ω–Ψ–Μ―É―²–Ψ–Ϋ–Ψ–≤–Ψ–≥–Ψ ―Ä–Β–Μ―¨–Β―³–Α, ―ç–Μ–Β–Φ–Β–Ϋ―²–Ψ–≤ ―¹―²―Ä―É–Κ―²―É―Ä–Ϋ–Ψ–≥–Ψ ―²–Β–Ϋ–Ζ–Ψ―Ä–Α –Η –Ζ–Ϋ–Α―΅–Β–Ϋ–Η–Ι –Μ–Ψ–Κ–Α–Μ―¨–Ϋ―΄―Ö –≤–Ψ–Μ–Ϋ–Ψ–≤―΄―Ö ―΅–Η―¹–Β–Μ. –£ –Ψ―²–Μ–Η―΅–Η–Β –Ψ―² –Η–Ζ–≤–Β―¹―²–Ϋ―΄―Ö ―Ä–Α–Ζ―Ä–Α–±–Ψ―²–Ψ–Κ –Ω―Ä–Η–Ζ–Ϋ–Α–Κ–Ψ–≤–Ψ–Β –Ψ–Ω–Η―¹–Α–Ϋ–Η–Β ―³–Ψ―Ä–Φ–Η―Ä―É–Β―²―¹―è ―²–Ψ–Μ―¨–Κ–Ψ –Ω–Ψ –Η–Ϋ―³–Ψ―Ä–Φ–Α―²–Η–≤–Ϋ―΄–Φ ―³―Ä–Α–≥–Φ–Β–Ϋ―²–Α–Φ –Η–Ζ–Ψ–±―Ä–Α–Ε–Β–Ϋ–Η–Ι –Η –Ϋ–Β ―²―Ä–Β–±―É–Β―² –Ω―Ä–Β–¥–≤–Α―Ä–Η―²–Β–Μ―¨–Ϋ–Ψ–Ι ―¹–Β–≥–Φ–Β–Ϋ―²–Α―Ü–Η–Η –Ψ―²–¥–Β–Μ―¨–Ϋ―΄―Ö –Φ–Α–Ζ–Κ–Ψ–≤ –Κ–Η―¹―²–Η. –ü―Ä–Ψ–≤–Β–¥–Β–Ϋ―΄ –≤―΄―΅–Η―¹–Μ–Η―²–Β–Μ―¨–Ϋ―΄–Β ―ç–Κ―¹–Ω–Β―Ä–Η–Φ–Β–Ϋ―²―΄. –ü―Ä–Β–¥–Μ–Ψ–Ε–Β–Ϋ–Ϋ–Ψ–Β –Ω―Ä–Η–Ζ–Ϋ–Α–Κ–Ψ–≤–Ψ–Β –Ψ–Ω–Η―¹–Α–Ϋ–Η–Β –Ω–Ψ–Ζ–≤–Ψ–Μ–Η―² –Ω–Ψ–Μ―É―΅–Η―²―¨ –Κ–Ψ–Μ–Η―΅–Β―¹―²–≤–Β–Ϋ–Ϋ―É―é ―Ö–Α―Ä–Α–Κ―²–Β―Ä–Η―¹―²–Η–Κ―É ―¹―²–Η–Μ―è –Ε–Η–≤–Ψ–Ω–Η―¹–Η –Α–≤―²–Ψ―Ä–Α –Η –Ϋ–Α―Ä―è–¥―É ―¹ –¥―Ä―É–≥–Η–Φ–Η –≤–Η–¥–Α–Φ–Η –Η―¹―¹–Μ–Β–¥–Ψ–≤–Α–Ϋ–Η―è –Κ–Α―Ä―²–Η–Ϋ ―¹―³–Ψ―Ä–Φ–Η―Ä–Ψ–≤–Α―²―¨ –Α―²―Ä–Η–±―É―Ü–Η–Ψ–Ϋ–Ϋ–Ψ–Β –Ζ–Α–Κ–Μ―é―΅–Β–Ϋ–Η–Β.
–Ξ–Α―à–Η–Ϋ –Γ.–‰. –î–Η–Ϋ–Α–Φ–Η―΅–Β―¹–Κ–Α―è ―¹–Β–≥–Φ–Β–Ϋ―²–Α―Ü–Η―è –Ω–Ψ―¹–Μ–Β–¥–Ψ–≤–Α―²–Β–Μ―¨–Ϋ–Ψ―¹―²–Η –Κ–Α–¥―Ä–Ψ–≤ // –€–Α―à–Η–Ϋ–Ϋ–Ψ–Β –Ψ–±―É―΅–Β–Ϋ–Η–Β –Η –Α–Ϋ–Α–Μ–Η–Ζ –¥–Α–Ϋ–Ϋ―΄―Ö. 2013. T. 1, ⳕ 6. C. 787-795. –û–Ω–Η―¹―΄–≤–Α–Β―²―¹―è –Α–Μ–≥–Ψ―Ä–Η―²–Φ ―¹–Β–≥–Φ–Β–Ϋ―²–Α―Ü–Η–Η, –Ψ―¹–Ϋ–Ψ–≤–Α–Ϋ–Ϋ―΄–Ι –Ϋ–Β –Ϋ–Α –Ψ–¥–Ϋ–Ψ–Φ –Κ–Α–¥―Ä–Β, –Α –Ϋ–Α –Ω–Α―Ä–Β ―¹–Ψ―¹–Β–¥–Ϋ–Η―Ö –Κ–Α–¥―Ä–Ψ–≤ –Η–Ζ –≤–Η–¥–Β–Ψ–Ω–Ψ―¹–Μ–Β–¥–Ψ–≤–Α―²–Β–Μ―¨–Ϋ–Ψ―¹―²–Η. –ü–Ψ ―¹―Ä–Α–≤–Ϋ–Β–Ϋ–Η―é ―¹ –Ψ–±―΄―΅–Ϋ–Ψ–Ι, ―¹―²–Α―²–Η―΅–Β―¹–Κ–Ψ–Ι ―¹–Β–≥–Φ–Β–Ϋ―²–Α―Ü–Η–Β–Ι –Κ–Α–Ε–¥–Ψ–≥–Ψ –Κ–Α–¥―Ä–Α –Ω–Ψ-–Ψ―²–¥–Β–Μ―¨–Ϋ–Ψ―¹―²–Η, –Κ–Α―΅–Β―¹―²–≤–Ψ –Ζ–Ϋ–Α―΅–Η―²–Β–Μ―¨–Ϋ–Ψ –Ω–Ψ–≤―΄―à–Α–Β―²―¹―è. –ü―Ä–Η ―¹–Ψ―Ö―Ä–Α–Ϋ–Β–Ϋ–Η–Η ―²–Ψ–Ι –Ε–Β –Ω–Ψ–≥―Ä–Β―à–Ϋ–Ψ―¹―²–Η, –Κ–Ψ–Μ–Η―΅–Β―¹―²–≤–Ψ ―¹–Β–≥–Φ–Β–Ϋ―²–Ψ–≤ ―É–¥–Α–Β―²―¹―è ―¹–Ψ–Κ―Ä–Α―²–Η―²―¨ –≤ –Ϋ–Β―¹–Κ–Ψ–Μ―¨–Κ–Ψ –¥–Β―¹―è―²–Κ–Ψ–≤ ―Ä–Α–Ζ. –Δ–Η–Ω–Η―΅–Ϋ–Ψ–Β –Κ–Ψ–Μ–Η―΅–Β―¹―²–≤–Ψ ―¹–Β–≥–Φ–Β–Ϋ―²–Ψ–≤, –Ϋ―É–Ε–Ϋ―΄―Ö –¥–Μ―è –Ω–Ψ–Μ―É―΅–Β–Ϋ–Η―è –Ω―Ä–Η–Β–Φ–Μ–Β–Φ–Ψ–Ι –Ω–Ψ–≥―Ä–Β―à–Ϋ–Ψ―¹―²–Η ―É–Φ–Β–Ϋ―¨―à–Α–Β―²―¹―è ―¹  –¥–Ψ
–¥–Ψ 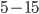 .
.
